CodeX: C++
C++, Introduction for Entry Level Programmers is the first course in the CodeX series.
Not everything in this guide is designed to make sense at first, but it will always be covered later.
This is an introductory course designed to teach entry-level programmers the basics of the C++ programming language. The course will cover topics such as basic data types and operations, conditionals, loops, functions and classes, as well as advanced concepts like pointers, memory management, threads, and RAII. Throughout the course, you will learn how to write code in C++. People taking this course should (but are not required to) have a basic understanding of fundamentals, no prior experience with C++ is necessary.

To the extent possible under law,
CodeX
has waived all copyright and related or neighboring rights to
CodeX: C++, Introduction for Entry Level Programmers.
This work is published from:
United States.
Introduction to C++
C++ is like the Swiss Army Knife of programming languages! It's a powerful, versatile, and efficient language that can be used for a wide variety of applications. From creating high-performance game engines to developing sophisticated operating systems, C++ has got you covered.
What is C++ Good For?
-
Performance: When it comes to raw power, C++ is one of the top dogs in the programming world. Its ability to work close to the hardware level allows developers to create blazingly fast applications.
-
Systems Programming: Operating systems, device drivers, and embedded systems often require precise control over hardware resources. With its low-level capabilities and fine-grained memory management features, C++ excels at these tasks.
-
Game Development: The gaming industry loves C++ for its speed and flexibility. Many popular game engines like Unreal Engine and Unity support C++ for creating performance-critical components.
-
Large-scale Applications: Companies with complex software infrastructures value the scalability of C++. Its modular nature makes it easier to manage codebases with millions of lines of code.
-
Cross-platform Development: Write once, compile anywhere! Since it doesn't rely on a virtual machine or interpreter (like Java or Python), you can create native executables for different platforms without sacrificing performance.
What is C++ Not So Good For?
Despite its many strengths, there are some areas where other languages might be more suitable:
-
Rapid Prototyping: Due to its complexity and static typing system, writing code in C++ can take longer than in more dynamic languages like Python or JavaScript. If you need quick results or want to test ideas rapidly, another language might serve you better.
-
Web Development: While it's possible to write web applications in C++, other languages like JavaScript (Node.js), Ruby (Ruby on Rails), or Python (Django) offer more comprehensive libraries and frameworks for web development.
-
Beginner-friendliness: The steep learning curve of C++ can intimidate novices. For those just starting to learn programming, languages like Python or JavaScript might provide a gentler introduction.
A Simple Starting Program
Ready to dip your toes in C++? Here's a classic "Hello, World!" example:
#include <iostream>
int main() {
std::cout << "Hello, World!" << std::endl;
return 0;
}
This program demonstrates the basics of C++ syntax: including the iostream library for input/output operations, defining the entry point (main function), and using the std::cout object to print "Hello, World!" to the console. Finally, we return 0, signaling successful execution.
What is C++
Some of the topics on this page may be confusing depending on your level of experience; however, they will all be explained in this course.
C++ is a versatile, high-performance programming language designed for systems programming. It was developed by Bjarne Stroustrup in 1979 as an extension of the C language, with the goal of providing efficient and flexible support for object-oriented programming, low-level memory manipulation, and generic programming.
Being a statically-typed language, C++ enforces type checking at compile-time rather than run-time. This means that the programmer must explicitly define the data types of variables before using them in the program. The benefit of this approach is that it allows for better performance and helps catch errors early in the development process.
C++ offers many features that make it suitable for a wide range of applications:
-
Object-Oriented Programming (OOP): This paradigm allows you to model real-world entities as objects with properties (attributes) and behavior (methods). OOP promotes code reusability and maintainability through inheritance, encapsulation, and polymorphism.
-
Generic Programming: C++ provides powerful template support that enables you to write reusable algorithms and data structures without sacrificing performance. Templates allow you to create functions or classes that work with different data types without having to rewrite the same code for each specific type.
-
Low-level Memory Manipulation: As a systems language, C++ grants direct access to computer memory through pointers. This feature makes it possible to write highly optimized code for memory-intensive tasks or interfacing with hardware devices.
-
Standard Template Library (STL): The STL is a collection of template classes and functions provided by the C++ Standard Library. It includes containers (like vectors, lists, maps), algorithms (sort, find), iterators, and other utilities that simplify common programming tasks.
Despite its numerous advantages, there are some complexities associated with learning and mastering C++. For instance:
-
Syntax: The syntax of C++ can be quite daunting for beginners, especially when dealing with pointers, references, and templates.
-
Memory management: C++ requires manual memory management, which means that the programmer is responsible for allocating and deallocating memory as needed. This can lead to errors such as memory leaks or segmentation faults if not done correctly.
-
Backward compatibility: C++ maintains a high degree (but not 100%) of backward compatibility with its predecessor, the C language. This results in a larger set of features and libraries available but also introduces some complexities when trying to understand older code or using legacy libraries. This provides the useful benefit of being able to use C code and C libraries with C++.
Key Terms
Some key terms you should know
The Compiler
When you start learning C++ programming, one term you will come across frequently is the "compiler." But what exactly is a compiler, and how does it work? This section will help you understand the role of a compiler in the C++ programming process.
What is a Compiler?
To understand the concept of a compiler, let's use an analogy. Imagine you're an author who wants to write a book. You can speak and write English fluently, but the printing press only understands a special language to print your book, you need to translate it from English to that language.
In the world of programming, the C++ language is like English, and the machine (computer) only understands a low-level language called "machine code" (the printing press language in our analogy). A compiler is a special tool that translates your C++ code into machine code, which the computer can understand and execute.
So, a compiler is a program that converts the C++ code you write into a format that the computer can understand and execute.
How Does a Compiler Work?
When you write a C++ program, you create a text file containing the C++ code. This file is called the "source code." To make your computer execute this code, you need to follow a few steps:
- Compilation: The compiler reads the source code, checks it for errors, and translates it into machine code.
- Linking: After the compilation, the machine code is combined with any additional libraries and resources needed for the program to run correctly. This process is called "linking," and it produces an "executable" file.
- Execution: You can now run the executable file, and the computer will execute the program according to your C++ code.
Let's go through these steps in more detail.
Compilation
When you write a C++ program, you use variables, functions, and other elements from the C++ language. The compiler's job is to take your high-level C++ code and convert it into low-level machine code that the computer can understand.
During this process, the compiler also checks your code for any syntax errors, such as missing semicolons, unmatched parentheses, or undeclared variables. If it finds any errors, it will report them, and you'll need to fix them before the compiler can successfully compile your code.
Linking
Once the compiler has translated your C++ code into machine code, it needs to combine it with any libraries or resources you've used in your program. For example, if you've used a function from the C++ Standard Library, the linker will make sure that the machine code for that function is included in the final executable.
The linker also resolves any references between different parts of your code, such as function calls or global variables. Once the linking process is complete, you'll have an executable file that contains all the necessary machine code for your program.
Execution
Now that you have an executable file, you can run it on your computer. When you execute the file, the computer will follow the instructions in the machine code, which corresponds to the C++ code you wrote. This is how your C++ program comes to life and performs the tasks you designed it to do.
Popular C++ Compilers
There are several popular compilers available for C++ programming:
- GNU Compiler Collection (GCC): A widely-used, open-source compiler that supports multiple languages, including C++.
- Microsoft Visual C++ (MSVC): A compiler included with Microsoft Visual Studio, a popular integrated development environment (IDE) for Windows.
- Clang: A compiler based on the LLVM project, known for its fast compilation speed and helpful error messages.
Each compiler may have its unique features and optimizations, but they all serve the same purpose: to convert your C++ code into machine code that your computer can understand and execute.
Development Environments
Before you dive into writing your first lines of code, it's essential to set up a development environment that will make your C++ journey enjoyable and productive.
Some features you can expect in a Development Environment are:
- Intellisense: Intelligent code completion suggestions as you type, making it easier to write code quickly and efficiently.
- Debugger: Debugger that can quickly identify issues in your code.
- Code Editor: Code editor that supports syntax highlighting, making it easy to read and understand your code.
- Version Control Integration: Git version control integration so that you can manage your project history effortlessly.
Environments
-
Visual Studio is an excellent Integrated Development Environment (IDE) developed by Microsoft. It offers a user-friendly interface, making it one of the most popular choices among beginner programmers. It is only supported on Windows.
-
Visual Studio Code is a code editor with support for development operations like debugging, task running, and version control. It aims to provide just the tools a developer needs for a quick code-build-debug. With the addition of extensions, it can be tailored for C++ development, making it a versatile tool for programmers.
Installing Visual Studio IDE
In this section, we'll guide you through the simple steps of installing Visual Studio IDE on your machine. Buckle up and let's get started!
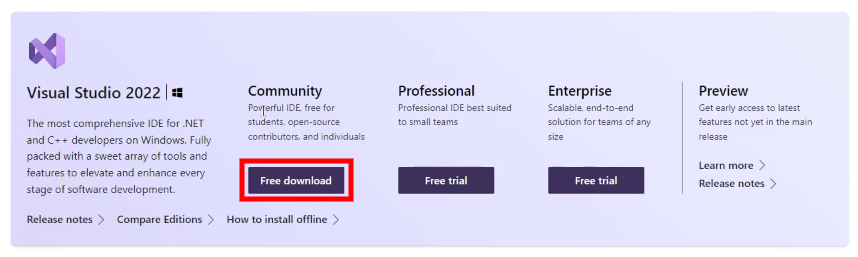
Download the Installer
First things first - head over to the Visual Studio download page and select the edition that suits you best. For beginners, we recommend Visual Studio Community, which is free for individual developers, open-source projects, academic research, education, and small professional teams.
Click on "Free download" for Visual Studio Community Edition and save the installer file on your computer.
Run the Installer
Locate the downloaded installer file (usually in your Downloads folder) and double-click it to run. A User Account Control prompt may appear asking if you want to allow the app to make changes to your device; click "Yes."
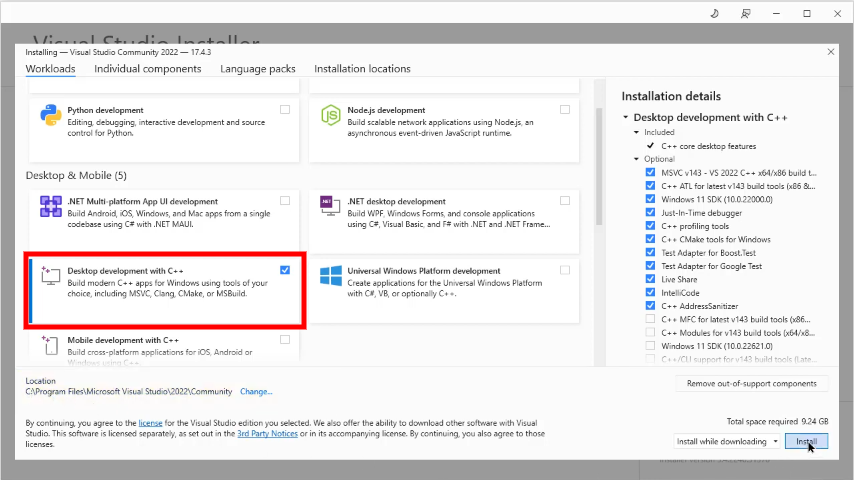
Customize Your Installation
Once the installer starts, it'll present a list of workloads (a set of features tailored for specific development tasks). Find and select "Desktop development with C++" - this includes everything you need for C++ programming.
Feel free to explore other workloads too! If you're interested in game development or cross-platform mobile development, Visual Studio has got you covered.
After selecting workloads, click on "Install" at the bottom right corner of the installer window. Grab a cup of coffee while Visual Studio installs all necessary components!
Launch Visual Studio IDE
When the installation is complete, click on "Launch" to start Visual Studio IDE. It'll open a welcome screen where you can sign in with your Microsoft account or create one. Signing in helps synchronize your settings and preferences across devices.

Create Your First C++ Project
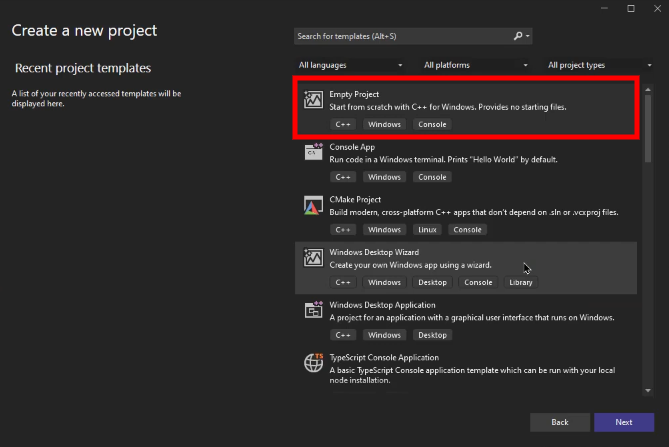
Congratulations! You've successfully installed Visual Studio IDE, and now it's time to create your first C++ project:
- Click on "Create a new project" from the Welcome screen.
- Choose "Empty Project" under the "C++" filter, then click "Next."
- Give your project a name and choose a location to save it.
- Click on "Create."
You're all set! Now go ahead and write your first lines of C++ code in the Source Files folder by creating a new .cpp file. The world of programming awaits!
Setting Up the Visual Studio Code Environment
In this guide, you will learn how to install Visual Studio Code, the necessary build tools, and CMake on your system. We'll outline the steps for different operating systems, although the general instructions are similar across platforms.
Installation of C++ Tools
Windows
Follow these steps to install the Build Tools for Visual Studio:
-
Navigate to the Visual Studio download page.
-
Choose Visual Studio Community—a free option for individual developers—and click "Free download."
-
Save the installer file to your computer.

-
Execute the installer and select the "Desktop development with C++" workload, which includes the necessary MSVC compiler, Windows SDK, and C++ components.

Linux
For Linux distributions, install the build-essential package which provides the GNU C/C++ compiler and other development tools:
- Ubuntu:
sudo apt update && sudo apt install build-essential - Arch Linux:
sudo pacman -Sy base-devel(Note: The package isbase-devel, notbuild-essentialwhich is for Debian-based systems.) - Fedora:
sudo dnf install make automake gcc gcc-c++ kernel-devel
macOS
For macOS, install the Xcode command line tools to obtain the required Clang C++ compiler and other essential tools:
xcode-select --install
Installation of CMake
CMake is an essential suite of open-source tools used to build, test, and package software. It facilitates building and running C++ programs and provides autocompletion in VSCode.
Windows
- Download the CMake installer for Windows from the CMake download page.
- Upon executing the installer, select "Add CMake to the system PATH for all users" or "Add CMake to the system PATH for the current user" during the installation process.
Linux
Use your distribution's package manager to install CMake. Here are the commands for common distributions:
- Ubuntu:
sudo apt update && sudo apt install cmake - Arch Linux:
sudo pacman -Sy cmake - Fedora:
sudo dnf install cmake
macOS
The easiest way to install CMake on macOS is through Homebrew:
brew install cmake
For Homebrew installation, visit https://brew.sh/.
Installation of Visual Studio Code (VSCode)
VSCode is a versatile and lightweight IDE that supports C++ development. Here's how to install it:
Windows
- Access the VSCode download page and fetch the Windows installer.
- Execute the installer and accept the default settings unless you have specific preferences.
Linux
Ubuntu and Debian-Based Distributions
Download the .deb package for Debian/Ubuntu from the VSCode download page.
Then in the terminal:
cd ~/Downloads
sudo dpkg -i code_*.deb
# Run the following if there are dependency issues:
sudo apt-get install -f
Fedora, Red Hat, and RPM-Based Distributions
Fetch the .rpm package and use the terminal:
cd path/to/download
sudo dnf install code_*.rpm
Arch Linux and Arch-Based Distributions
In the terminal, choose from the community repository or the official one for the open-source build (VSCode OSS):
sudo pacman -Syu code # For Visual Studio Code
# Or
sudo pacman -Syu code-oss # For Visual Studio Code - OSS
macOS
- Navigate to the VSCode download page and acquire the macOS version.
- Open the
.zipfile, which will unpackVisual Studio Code.app. - Move
Visual Studio Code.appto your "Applications" folder. - Start VSCode from the "Applications" folder or via Spotlight.
Configuring VSCode Extensions
- Open up Visual Studio Code.
- Access the Extensions view by clicking the square icon on the sidebar or using
Ctrl+Shift+X. - Install the following essential extensions:
- clangd for C/C++ language support
- CMake to enable CMake language features
- CMake Tools to enhance the CMake experience
Creating Your First C++ Project
Let's put your setup to the test by creating a simple C++ project:
- Launch VSCode and go to the "File" menu. Choose "Open Folder..." to make a directory for your new project.
- In your project folder, create a file named
CMakeLists.txtand configure your project:cmake_minimum_required(VERSION 3.10) project(MyFirstProject) add_executable(MyFirstProject main.cpp) - Create a
main.cppfile and paste the code belo:#include <iostream> int main() { std::cout << "Hello world!" << std::endl; return 0; } - Press
Ctrl + Pto bring up the command palette and run> CMake: Configureto configure your project. (Remember to add each new source file toadd_executableand reconfigure afterwards.) - Use the run button at the bottom of the VSCode window to execute your application.
Congratulations! Your development environment is now set up, and you are ready to dive into C++ programming with Visual Studio Code.
Basic Concepts
In this section, you will be introduced to some fundamental concepts in C++
- Data Types
- Variables
- Strings and Arrays
- Constants and Literals
- The Main Function
- Statements and Expressions
- Input/Output
Comments in C++
Comments are an essential part of programming, as they allow you to insert notes, explanations or reminders directly into your code. In C++, there are two types of comments: single-line and multi-line comments.
Single-line comments
Single-line comments begin with two forward slashes (//) and continue until the end of the line. Any text following the // on the same line will be considered a comment and will not be executed by the compiler.
Multi-line comments
Multi-line comments begin with a forward slash followed by an asterisk (/*) and end with an asterisk followed by a forward slash (*/). Any text between these delimiters will be considered a comment, even if it spans multiple lines.
int main() {
/*
* This is a multi-line comment.
* It can span multiple lines.
*/
return 0;
}
Good commenting practices make your code more readable and maintainable, so always remember to include meaningful comments when writing your programs.
Data Types
Imagine you're a chef in the kitchen, and you have many ingredients to cook with. These ingredients are like the basic building blocks for your dish. Similarly, in C++, data types are the basic building blocks for your program. They are the way we represent different kinds of data in our code, like numbers, characters, and strings (text).
Fundamental Data Types
C++ provides several fundamental data types that can be used to represent different kinds of data. These data types can be broadly categorized into the following groups:
- Integer types: These data types are used to represent integer values (whole numbers). Some examples are
int,short int,long int, andlong long int. - Floating-point types: These data types are used to represent real numbers (numbers with a fractional/decimal part). Examples include
floatanddouble. - Character types: These data types are used to represent single characters, like 'a' or '7'. The most common character type is
char. - Boolean type: This data type is used to represent true or false values. It is called
bool.
Each of these types has an unsigned version (e.g., unsigned int) that can only store positive numbers and zero. The range of unsigned types is double that of their signed counterparts because they don't need to store negative values.
Integer Types
Think of integer types as the different sizes of measuring cups. They can hold varying amounts of data (or numbers). The most commonly used integer types in C++ are:
short int: Can store small integer values, typically between-32,768and32,767.int: Can store a wide range of integer values, typically between-2,147,483,648and2,147,483,647.long int: Can store large integer values, typically between-9,223,372,036,854,775,808and9,223,372,036,854,775,807.long long int: Can store very large integer values, with at least the same range aslong.
Floating-Point Types
Floating-point types are like measuring cups with a built-in scale – they can hold both whole numbers and decimals. C++ provides two floating-point types:
float: Can store single-precision floating-point numbers (about 7 decimal digits of accuracy).double: Can store double-precision floating-point numbers (about 15 decimal digits of accuracy).long double: Can store very large double-precision floating-point values.
double provides greater precision than float, but it also consumes more memory.
Character Types
Character types are like individual letters or symbols that you can use to form words and sentences. In C++, the most common character type is char. It can store a single character, like A, z, or #.
Characters in C++ are encoded using the ASCII (American Standard Code for Information Interchange) system, which assigns a unique number to each character. This means that, under the hood, a char is actually an integer type that can store values between 0 and 255.
Boolean Type
The boolean type is like a simple light switch – it can be either on (true) or off (false). In C++, the boolean type is called bool.
bool variables can only store two values: true or false. They are commonly used to represent the outcome of a condition or to control the flow of a program.
Pointer Types
In C++, pointers are a special type of data type that can store the memory address of another variable. They provide a way to indirectly access and manipulate the value stored at that memory address.
A pointer is declared by specifying the data type it points to, followed by an asterisk (*).
It is important to note that the data type specified when declaring a pointer is not the type of the pointer itself but rather the type of data it will point to. This means that int* is a pointer that can store the address of an int variable, while char* can store the address of a char variable.
We will discuss these more in a later chapter
Strings and Arrays
Arrays are a list type that stores multiples of the same item. For example, strings are an array of char which you would use for storing words or sentances.
This will be explored in a later chapter, but it is reccomended to read variables first.
Variables
Think of a variable as a container or a box that can store a specific type of data. This data can be a number (integer or decimal), a character, or any other data type. In C++, variables are used to store and manipulate data that can be used in various parts of a program.
Let's use an analogy to understand variables better. Imagine you are running a store, and you have several shelves to store different types of items. Each shelf is labeled with a unique name, and you can only store items of a specific type on that shelf. In the world of programming, each shelf represents a variable, the unique name is the variable's name, and the type of items that can be stored represents the data type of that variable.
Declaring Variables
Before we can use a variable in a C++ program, we need to declare it. Declaring a variable involves specifying its data type and giving it a name. The general syntax for declaring a variable is as follows:
data_type variable_name;
Data types have been explained the data types section, so you should have a basic understanding of them. Here's a quick example of declaring an integer variable called age:
int age;
In this example, int is the data type, and age is the variable name. This declaration tells the compiler that we have created a variable named age that can store integer values.
You can also declare multiple variables of the same data type on a single line by separating them with commas:
int x, y, z;
This line declares three integer variables: x, y, and z.
Assigning Values to Variables
After declaring a variable, we can assign a value to it using the assignment operator =. Here's an example of assigning the value 25 to the previously declared age variable:
age = 25;
Now the variable age contains the value 25. It's also possible to declare a variable and assign a value to it in the same line:
int age = 25;
This line declares an integer variable called age and assigns the value 25 to it.
Using Variables
Once a variable has been declared and assigned a value, you can use it in various ways in your program. For example, you can perform calculations with it, use it in conditional statements, or display its value on the screen.
Here's an example of using the age variable to calculate the number of days someone has lived:
int age = 25;
int days_lived = age * 365;
In this example, we multiply the value of age by 365 to calculate the number of days someone has lived and store the result in a new variable called days_lived.
Strings and Arrays
Arrays allow you to store multiple elements of the same data type together, while strings are a special kind of array that stores multiple characters.
Arrays
Think of an array as a row of storage lockers, where each locker can store an item of the same type. An array is a collection of elements of the same data type, stored together in a continuous (sequential) block of memory. You can access and modify individual elements in an array using their index, which represents their position in the array.
Declaring an Array
To declare an array in C++, you need to specify its data type, followed by its name and the size of the array in square brackets. For example, to declare an integer array of size 5, you can write:
int myArray[5];
This creates an array named myArray that can store 5 integer values.
Accessing Array Elements
To access an element in an array, you can use its index. Array indices in C++ start at 0, so the first element is at index 0, the second element is at index 1, and so on. For example, to assign a value to the first element of myArray, you can write:
myArray[0] = 42;
To access the value stored in the first element of myArray, you can use:
int firstValue = myArray[0];
Array Initialization
You can initialize an array when you declare it by specifying its elements inside curly braces. For example, to declare and initialize an integer array, you can write:
int myArray[] = {1, 2, 3, 4, 5};
In this case, you don't need to specify the size of the array, as the compiler will automatically determine it based on the number of elements you've provided.
Strings
Strings are sequences of characters used to represent text. In C++, strings are essentially arrays of characters, terminated by a special character called the null terminator (\0). The null terminator indicates the end of the string.
Declaring and Initializing Strings
You can declare and initialize a string in C++ using either an array of characters or the std::string class provided by the C++ Standard Library. Here are two ways to declare and initialize a string:
// Using a character array
char myString[] = "Hello, world!";
// Using the std::string class
#include <string>
std::string myString = "Hello, world!";
The std::string class provides many useful functions for working with strings, such as finding the length of a string, concatenating strings, and comparing strings. It is generally recommended to use std::string over character arrays when working with strings in C++.
Accessing String Characters
You can access individual characters in a string using the same indexing method as arrays. For example, to access the first character of a std::string, you can write:
char firstChar = myString[0];
Constants and Literals
Constants
Constants are like unwavering pillars that hold up your code structure. They are fixed values that never change throughout the execution of a program. Once you declare a constant, it remains steady and immovable.
You might wonder why we need constants when we have variables. Well, imagine if all the pillars in your building were made out of shape-shifting material! Sounds chaotic, right? In programming too, sometimes you want to ensure that certain values remain steadfast and unaffected by any changes during runtime.
To create a constant in C++, you use the const keyword before declaring a variable:
const int speedOfLight = 299792;
Now you can be confident that speedOfLight will always remain constant at 299792 km/s throughout your program!
Literals
Literals are like the most basic units in our construction analogy - think of them as individual bricks or planks of wood. They represent fixed values directly written into your code without any accompanying names or identifiers.
Literals can be classified into several categories based on their data types:
-
Integer literals: These are whole numbers without any decimal points or fractional parts.
42 // An integer literal (the meaning of life) -100 // Another integer literal -
Floating-point literals: These represent real numbers with decimal points or exponents.
3.14 // A floating-point literal -0.001 // Another floating-point literal 6.022e23 // Scientific notation for large/small numbers (Avogadro's number!) -
Character literals: These are single characters enclosed within single quotes.
'A' // A character literal '9' // Another character literal (yes, even digits can be characters!) '\n' // An escape sequence representing a newline character -
String literals: These are sequences of characters enclosed within double quotes.
"Hello, World!" // A string literal "C++ is awesome!" // Another string literal "I'm Craving nachos\n" // String literals can also contain escape sequences! -
Boolean literals: There are only two Boolean literals:
trueandfalse.true // A Boolean literal representing truthiness! false // A Boolean literal representing falseness :(
Depending on your experience level, the last two below may not make any sense. We will talk more about this in future chapters.
-
Pointer literals: A pointer literal represents a null pointer value, which is a special value indicating that the pointer isn't pointing to any valid memory location. This will be explored more in future chapters.
nullptr // A pointer literal in C++11 and later NULL // A pointer literal in older C++ versions (defined as 0) -
User-defined literals: Starting from C++11, you can create your own custom literals using user-defined literal operators.
#include <iostream> constexpr long double operator"" _cm(long double x) { return x * 10; } constexpr long double operator"" _m(long double x) { return x * 1000; } int main() { long double height = 3.4_cm; // User-defined literal for centimeters long double length = 1.2_m; // User-defined literal for meters std::cout << "Height: " << height << " mm" << std::endl; std::cout << "Length: " << length << " mm" << std::endl; return 0; }In this example, we've defined two user-defined literals
_cmand_mto convert distances into millimeters.
The Main Function in C++
In C++, the main function is the starting point of your program. It is where your program begins execution. Every C++ program must have a main function, as it is the first function that gets executed when your program runs. The main function is responsible for managing the flow of your program and calling other functions as needed.
Let's look at a simple C++ main function:
main.cpp#include <iostream> int main() { std::cout << "Hello, World!" << std::endl; return 0; }
In this example, the main function consists of several parts:
-
#include <iostream>: This is a preprocessor directive that tells the compiler to include the iostream header file. The iostream header file is part of the C++ Standard Library and is required when you want to use input and output (I/O) operations, such as reading from the keyboard or writing to the screen. -
int main(): This is the main function itself. It is a function namedmain, and it returns anint(integer) value. When you seeint main(), it means that the main function takes no arguments and returns an integer. The parentheses()indicate that this is a function, and the curly braces{}define the body of the function. -
std::cout << "Hello, World!" << std::endl;: This is a statement that outputs the string "Hello, World!" to the console.std::coutis an object that represents the standard output stream (usually the console). The<<operator is used to send data to the output stream. In this case, we are sending the string "Hello, World!" followed by a newline, represented bystd::endl. Thestd::part is a namespace specifier that tells the compiler to look forcoutandendlin thestdnamespace, which is part of the C++ Standard Library.-
The
<<is an example of an operator. Operators are special symbols that represent specific operations, such as arithmetic, comparison, or assignment. In this case, the<<operator is known as the stream insertion operator. It is used to insert data, such as a string, into an output stream.You could use regular function calls to achieve the same result. In this case, you would replace the
<<operator with theputandwritemember functions ofstd::cout. Here's an example:std::cout.write("Hello, World!", 13); std::cout.put('\n');This code snippet uses the
writefunction to output the "Hello, World!" string and theputfunction to output the newline character. Note that thewritefunction requires the length of the string as its second argument.
-
-
return 0;: This is a return statement that indicates the end of the main function. The value0is returned to the operating system, signifying that the program has executed successfully. A non-zero value would indicate an error.
Statements and Expressions in C++
In C++ programming, statements and expressions are the building blocks of your code.
Expressions
An expression is a piece of code that evaluates or calculates a value. It consists of variables, constants, and operators (+, -, *, /, etc.) combined in a meaningful way. Think of expressions as a simple math equation or a question that the program needs to answer.
Here are some examples of expressions:
5 + 3 // add
x * y // multiply
a > b // comparison
Statements
A statement, on the other hand, is a complete line of code that performs an action. It usually consists of one or more expressions joined together. Statements end with a semicolon (;), which tells the compiler that the line is complete.
Here are some examples of statements:
int x = 5; // Declaration and assignment statement
x = x + 3; // Assignment statement
std::cout << x; // Output statement (or function call)
Types of Statements
C++ has several types of statements, including:
-
Declaration Statements: These statements declare and define variables and their types. For example:
int age; // Declares an integer variable named 'age' std::string name; // Declares a string variable named 'name' -
Assignment Statements: These statements assign a value to a variable. For example:
age = 25; name = "John Doe"; -
Control Statements: These statements control the flow of your program, such as loops and conditional statements. For example:
if (age > 18) { std::cout << "You are an adult!"; } else { std::cout << "You are a child!"; } // Subtract age until it is no longer greater than 0. while (number > 0) { std::cout << number << std::endl; number--; // Equivalent to `number = number - 1;` } -
Function Call Statements: These statements call or invoke a function in your program. For example:
int result = add_numbers(5, 3); // Calls the 'add_numbers' function with arguments 5 and 3
Combining Statements and Expressions
In C++ programs, you'll often see expressions and statements combined. For example:
int x = 5; // Declaration and assignment statement
int y = x * 2 + 1; // Declaration, assignment, and expression combined
In this example, the expression x * 2 + 1 is combined with the declaration and assignment statement to create a new statement.
Input/Output
Streams: The Rivers of Data
Imagine your program as an island surrounded by streams (rivers) that bring data to it and take data away from it. These rivers are like communication channels between your program and the outer world, including devices such as keyboards, monitors, files, and more! In C++, these "rivers" are called streams.
There are three main types of streams:
- Input Stream (
istream) - Brings data into your program from various sources. - Output Stream (
ostream) - Takes data from your program and sends it to different destinations. - I/O Stream (
iostream) - A combination of input and output streams for bidirectional communication.
The Journey Begins: iostream
Before we dive into the fun part (coding), let's understand some essential tools for I/O operations in C++. We need two magical keys from the iostream library:
cin: Our trusty friend for reading input data.cout: Our reliable companion for displaying output data.
You may have seen this in previous chapters.
To include these keys in our program, simply add this line at the beginning:
#include <iostream>
Talking to Your Program: Reading Input
Let's start by making our program ask for our name! To do that, we use cin, followed by the extraction operator (>>).
Here's how you can read a user's name:
#include <iostream>
#include <string>
int main() {
std::string name;
std::cout << "What is your name? ";
std::cin >> name;
return 0;
}
In this example, we first declared a variable name of type std::string. Then, using cin, we read the input and stored it in the name variable.
Sharing Your Thoughts: Displaying Output
Now that we have our user's name, let's greet them! This time, we'll use cout followed by the insertion operator (<<).
Here's how you can display a greeting message:
#include <iostream>
#include <string>
int main() {
std::string name;
std::cout << "What is your name? ";
std::cin >> name;
std::cout << "Hello, " << name << "! Nice to meet you!" << std::endl;
return 0;
}
In this example, we used cout to display a greeting message containing the user's name. We also added std::endl, which creates a newline character, making our output more organized.
Putting It All Together: Let's Chat!
Congratulations! You've learned the basics of Input/Output in C++. As a reward for your efforts, let's create a mini-chat program where users can send messages and receive automatic responses:
#include <iostream>
#include <string>
int main() {
std::string username;
std::string message;
// Introduce ourselves and ask for their username
std::cout << "Welcome to C++ Chatbot!" << std::endl;
std::cout << "Please enter your username: ";
std::cin >> username;
// Start the chat loop
while (true) {
// Read user's message
std::cout << username << ": ";
std::cin.ignore();
std::getline(std::cin, message);
// Exit the chat if they type "bye"
if (message == "bye") {
break;
}
// Generate an automatic response
std::cout << "Chatbot: I hear you, " << username << "! You said: \""
<< message << "\"." << std::endl;
}
return 0;
}
And there you have it! A simple chatbot using C++.
C-style Input/Output
C-style input/output (I/O) refers to the methods of handling data input and output in C++, derived from the C programming language. These I/O functions are provided by the cstdio library, which is a part of the C++ Standard Library. In this section, we will explore two basic functions for reading and writing data: printf for output and scanf for input.
Output with printf
printf is a function used to print formatted text to the console. It takes a format string as its first argument, followed by a variable number of additional arguments (if needed). The format string contains placeholders that are replaced by the corresponding values specified in the additional arguments.
#include <cstdio>
int main() {
int age = 25;
double height = 6.1;
// Printing an integer value
printf("I am %d years old.\n", age);
// Printing a floating-point value with one decimal place
printf("I am %.1f feet tall.\n", height);
return 0;
}
In this example, %d is used as a placeholder for an integer value, while %.1f is used as a placeholder for a floating-point value rounded to one decimal place.
Input with scanf
scanf is a function used to read formatted data from the console. Like printf, it takes a format string as its first argument; however, instead of printing values, it reads them from user input and stores them into specified variables.
It's essential to use the address-of operator (&) when passing variables to scanf, because it needs memory addresses in order to store values properly.
#include <cstdio>
int main() {
int age;
double height;
// Reading an integer value
printf("Enter your age: ");
scanf("%d", &age);
// Reading a floating-point value
printf("Enter your height (in feet): ");
scanf("%lf", &height);
// Printing the entered values
printf("You are %d years old and %.1f feet tall.\n", age, height);
return 0;
}
In this example, %d is used as a placeholder for reading an integer value, while %lf is used as a placeholder for reading a floating-point value, %s is a string placeholder.
Control Structure
Control structures are fundamental building blocks in programming that help manage the flow of execution in a program. They allow you to create complex logic and decision-making capabilities by selectively executing code based on specific conditions or repetitions. The main elements of control structures include:
-
Sequence: This is the default control structure where code is executed line by line in the order it appears.
-
Flow Control: These statements enable you to execute specific code blocks depending on whether certain conditions are true or false.
-
Jump Statements: Jump statements provide additional control over the flow of your program by transferring execution to another part of your code, skipping loop iterations, or ending loops prematurely.
Flow Control
Flow control in programs refers to the various methods used to manage the order and execution of code based on certain conditions or repetitions. Key elements of flow control include:
-
Conditional Statements: These include
if,if-else, andswitchstatements, which allow you to execute specific code blocks based on conditions being true or false. -
Loops: These include
for,while, anddo-whileloops, which enable you to execute a block of code repeatedly based on a specific condition or a predetermined number of iterations.
Conditional Statements
These allow you to control the flow of your program based on certain conditions. With conditional statements, you can add logic and decision-making capabilities to your code.
What are Conditional Statements?
Conditional statements are used to decide whether a specific block of code should be executed or not, depending on whether a certain condition is true or false. They form the backbone of many algorithms and programs.
In C++, we mainly use three types of conditional statements:
ifstatementif-elsestatementswitchstatement
Let's dive into each one in more detail!
The if Statement
The simplest type of conditional statement is the if statement. It checks if a condition is true, and if so, executes the code inside its block.
#include <iostream>
int main() {
int age = 17;
if (age >= 18) {
std::cout << "You are eligible to vote!";
}
return 0;
}
In this case, since age is less than 18, nothing will be printed.
The if-else Statement
The if-else statement adds another branch for when the condition is false.
#include <iostream>
int main() {
int age = 17;
if (age >= 18) {
std::cout << "You are eligible to vote!";
} else {
std::cout << "You are not eligible to vote yet.";
}
return 0;
}
In this case, since age is less than 18, the message "You are not eligible to vote yet." will be printed.
The switch Statement
The switch statement is used when you need to make a decision based on multiple discrete values of a variable. It's a cleaner alternative to using multiple nested if-else statements.
#include <iostream>
int main() {
int day = 3;
switch (day) {
case 1:
std::cout << "Monday";
break;
case 2:
std::cout << "Tuesday";
break;
case 3:
std::cout << "Wednesday";
break;
default:
std::cout << "Invalid day number!";
}
return 0;
}
In this case, since day is equal to 3, the output will be "Wednesday".
Ternary Operator
The ternary operator in C++ is a shorthand way of writing simple if...else statements. It's called "ternary" because it involves three operands.
It takes the following form:
condition ? expression_if_true : expression_if_false
If condition is true, then expression_if_true is evaluated and returned. Otherwise, expression_if_false is evaluated and returned.
#include <iostream>
int main() {
int a = 10;
int b = 20;
int min = (a < b) ? a : b;
std::cout << min << std::endl;
return 0;
}
In this example, the a < b condition checks if a is less than b. If so, it evaluates to a (the expression before the colon), and a is assigned to min. If the condition a < b is false (meaning b is less than a), then the expression after the colon (b) is evaluated and assigned to min.
This is an extremely useful operator that can help simplify your code when working with simple conditional expressions.
Loops
Loops allow you to execute a block of code repeatedly, making them perfect for repetitive tasks and reducing code duplication.
In C++, we mainly use three types of loops:
forloopwhileloopdo-whileloop
Let's explore each one in more detail!
The for Loop
The for loop is ideal when you know how many times you want the loop to run. Its syntax includes an initialization, a condition, and an update statement.
#include <iostream>
int main() {
for (int i = 0; i < 5; i++) {
std::cout << "Iteration: " << i << std::endl;
}
}
This loop will print the numbers from 0 to 4. The variable i is initialized with a value of 0, and as long as i < 5, the code inside the loop will execute, incrementing i by one after each iteration (using i++).
The while Loop
The while loop is great when you don't know how many times the loop should run, but you do have a condition that determines when it should stop.
#include <iostream>
int main() {
int number = 1;
while (number <= 10) {
std::cout << "Number: " << number << std::endl;
number++;
}
return 0;
}
This loop prints the numbers from 1 to 10. As long as the condition number <= 10 is true, the loop will keep executing and incrementing number.
The do-while Loop
The do-while loop is similar to the while loop, but with one key difference: it always executes the code inside the loop at least once, even if the condition is false from the start.
#include <iostream>
int main() {
int number;
do {
std::cout << "Enter a number between 1 and 10: ";
std::cin >> number;
} while (number < 1 || number > 10);
std::cout << "You entered a valid number: " << number << std::endl;
return 0;
}
In this example, we prompt the user for a number between 1 and 10. If they enter an invalid value, we continue asking until they provide a valid one. The code inside the loop will always execute at least once, ensuring that we have a valid input before moving on.
Go ahead and experiment with different types of loops to find out which one works best for your specific needs.
Jump Statements
Jump statements allow you to control the flow of your program by transferring execution to another part of your code. They are especially useful when working with loops and conditional statements.
In C++, we have four main types of jump statements:
breakcontinuereturngoto
Let's jump into each one in more detail!
The break Statement
The break statement is used to exit a loop or a switch statement prematurely, skipping any remaining iterations or cases.
#include <iostream>
int main() {
for (int i = 0; i < 10; i++) {
if (i == 5) {
break;
}
std::cout << "Iteration: " << i << std::endl;
}
return 0;
}
In this example, the loop will only print the numbers from 0 to 4. When i reaches 5, the break statement will be executed, and the loop will terminate immediately.
The continue Statement
The continue statement is used to skip the current iteration of a loop and move on to the next one, ignoring any code that comes after it in the loop body.
#include <iostream>
int main() {
for (int i = 0; i < 10; i++) {
if (i % 2 == 1) {
continue;
}
std::cout << "Even number: " << i <<std::endl;
}
return 0;
}
In this example, we're printing even numbers between 0 and 9. When encountering an odd number (i % 2 ==1), the continue statement skips the rest of the code inside the loop and proceeds directly to the next iteration.
The return Statement
The return statement is used to exit a function and return a value to the caller. It can also be used to jump out of loops and conditional statements within a function. You will become more familiar with return in the next section.
The goto Statement
The goto statement is used to transfer control to another part of your code. While it can be useful in some cases, it's generally discouraged due to its potential to make code harder to read and maintain.
#include <iostream>
int main() {
int count = 0;
start:
count++;
std::cout << "Iteration: " << count << std::endl;
if (count < 5) {
goto start;
}
std::cout << "Finished!" << std::endl;
return 0;
}
In this example, the goto statement transfers control back to the start: label after each iteration until count reaches 5. It's essentially creating a loop without using regular loop constructs.
While jumps can be powerful tools when used effectively, remember that readability and maintainability should always be prioritized when writing code.
Functions in C++
In C++, functions are blocks of code that perform a specific task and can be called (or invoked) from other parts of the program. Functions make code easier to understand, maintain, and reuse by breaking the program into smaller, modular components.
Terminology
Function definition: A function definition is a block of code that defines the function's behavior, including its input parameters, output, and the actual code that will be executed when the function is called.
Function declaration: A function declaration is a statement that provides information about the function like its name, return type, and input parameters, but not the actual implementation. It serves as an interface between the function definition and the code that calls the function.
Function call (or invocation): A function call is a statement in the program that requests the execution of a specific function. When a function is called, the control is transferred to the function definition, and after the function has finished executing, the control is returned to the point in the program where the function was called.
Parameters: Parameters, are the input values that a function receives when it is called. They are declared within the parentheses in the function definition and function declaration. When calling a function with values these are called arguments.
Return type: The return type is the data type of the value that a function returns after its execution. If a function does not return any value, its return type is void.
Syntax
Here is the basic syntax for declaring and defining a function in C++:
// Function declaration (prototype)
return_type function_name(parameter_type parameter1, parameter_type parameter2);
// Function definition
return_type function_name(parameter_type parameter1, parameter_type parameter2) {
// Function body (code to be executed)
...
return value; // Optional, depending on the return type
}
Example
#include <iostream>
// Function declaration
int sum(int a, int b);
int main() {
int x = 5, y = 10;
int result = sum(x, y); // Function call
std::cout << "The sum is: " << result << std::endl;
return 0;
}
// Function definition
int sum(int a, int b) {
int total = a + b; // Function body (code to be executed)
return total; // Return the result
}
In this example, we declare a function called sum with a return type of int and two input parameters of type int. The function definition provides the actual implementation of the sum function, which calculates the sum of the input parameters and returns the result. The sum function is called from the main function, and the result is printed to the console.
Key Points
- Functions help to modularize and reuse code, making it easier to understand and maintain.
- Functions have a name, return type, and input parameters.
- Functions are declared (prototyped) before they are called and defined separately.
- The return type of a function indicates the type of value it returns after its execution. If a function does not return any value, its return type is
void. - Function calls transfer control to the function definition and then return control to the point in the program where the function was called.
Header Files
While learning C++, you'll often come across the term "header files." In this section, we will discuss what header files are, why they are essential, and how to use them effectively in your C++ programs.
What are header files?
Header files are simply text files with the extension .h or .hpp that contain declarations of functions, classes, variables, constants, and other elements that you want to share across multiple source files (.cpp files) in your program. They allow you to separate the implementation (the actual code) from the interface (the declarations) of your program.
In other words, header files act as an interface that tells the compiler what functions, classes, and other elements are available for use without actually providing the implementation. This makes your code more organized, modular, and easier to maintain.
Why are header files important?
Header files play a crucial role in C++ programming for several reasons:
-
Modularity: By separating the declarations and implementations, you can create more maintainable and reusable code. Other developers can easily understand and use your code by looking at the header files without going through the entire implementation.
-
Code Sharing: Header files allow you to share code between multiple source files, reducing code duplication and making your program more efficient.
-
Easier Compilation: When you modify a source file, only that file needs to be recompiled, not the entire program. If you didn't use header files, any change to a function or class would require recompiling every file that uses it.
How to use header files in C++?
To use header files in your C++ program, you need to follow these steps:
-
Create a header file: Create a new text file with the extension
.hor.hpp. You can use any text editor to create a header file. -
Add declarations: Add the declarations of the functions, classes, variables, and other elements that you want to share across multiple source files in your program.
-
Include the header file: In the source files (
.cppfiles) where you want to use the elements declared in the header file, use the#includedirective followed by the name of the header file enclosed in double quotes (") or angle brackets (< >). For example:#include "my_header_file.h"or
#include <my_header_file.hpp>The double quotes are used for including custom header files that you create, while the angle brackets are mainly used for including standard library header files.
-
Implement the declared elements: In a separate source file (
.cppfile), provide the implementation for the elements declared in the header file.
The #include directive copy and pastes the header file into your source file (.cpp file). You may have issues if you end up having the same header file included more than once. To circumvent this, put #pragma once at the top of your header file.
Example
my_math_functions.h(header file)#pragma once // Function declarations int add(int a, int b); int subtract(int a, int b);
my_math_functions.cpp(source file with implementation)#include "my_math_functions.h" // Function implementations int add(int a, int b) { return a + b; } int subtract(int a, int b) { return a - b; }
main.cpp(source file that uses the functions)#include <iostream> #include "my_math_functions.h" int main() { int a = 10, b = 5; std::cout << "Sum: " << add(a, b) << std::endl; std::cout << "Difference: " << subtract(a, b) << std::endl; return 0; }
In this example, we have created a header file my_math_functions.h that contains the declarations for two functions add and subtract. We include this header file in both the implementation file my_math_functions.cpp and the main.cpp file, which uses the functions.
By using header files, we can separate the declarations and implementations of the functions, making our code more organized and easier to maintain.
Function Overloading
Function overloading is a concept in C++ that allows you to define multiple functions with the same name but with different parameter lists. This means that you can have several versions of a function, each performing a slightly different operation based on the number and types of parameters passed. This not only improves code readability but also makes it more organized and easier to maintain.
Let's explore this fantastic feature with some examples!
Why Do We Need Function Overloading?
Imagine you're working on a project where you need to find the sum of two numbers. Simple, right? Now, what if these numbers can be integers or doubles? You'd have to write two separate functions for each case: one for int and another for double. But what if there are more types involved? That's when function overloading is useful.
With function overloading, you can define multiple functions with the same name but different parameter lists, allowing them to work seamlessly together.
How Does It Work?
Function overloading works by letting the compiler choose the most suitable version of an overloaded function based on how it's called. The compiler does this by matching the number and types of arguments provided during a call with those specified in any available overloaded functions.
#include <iostream>
// Function overload #1 - Sum of two integers
int sum(int a, int b) {
return a + b;
}
// Function overload #2 - Sum of two doubles
double sum(double a, double b) {
return a + b;
}
int main() {
int result_int = sum(5, 6); // Calls the first overload
double result_double = sum(3.2, 4.1); // Calls the second overload
std::cout << "Sum of integers: " << result_int << std::endl;
std::cout << "Sum of doubles: " << result_double << std::endl;
return 0;
}
In this example, we defined two overloaded sum functions. The first one takes two int parameters while the second one takes two double parameters. When we call these functions with integer or double values, the compiler automatically selects the appropriate version based on the argument types.
Best Practices
While function overloading can be incredibly useful, there are some best practices you should follow:
- Use descriptive parameter names: This makes it easier to understand what each parameter does and helps avoid confusion.
- Maintain consistency in parameter order: Keeping a consistent order of parameters across different overloads will make your code much more readable and manageable.
- Avoid ambiguous overloads: Sometimes, an ambiguous situation may arise when multiple overloads could match a given call. In such cases, the compiler cannot determine which version to use and will throw an error.
Conclusion
Function overloading is an awesome feature in C++ that allows you to define multiple versions of a function with different parameter lists. It improves code readability and organization by allowing you to write cleaner and more efficient code.
Recursion
Recursion occurs when a function calls itself directly or indirectly. It's like inception but for functions!
A good example for this is the factorial function.
flowchart LR
A["Start"] --> B["Function: factorial(n)"]
B --> C{Is n <= 1?}
C -->|Yes| D["Return 1 + sum"]
C -->|No| E["Call factorial(n-1)"]
E --> B
Imagine you're climbing a staircase, and at each step, you can either take one or two steps. How many ways are there to reach the top? This problem can be elegantly solved using recursion!
Here's how we might write this function in C++:
int countWays(int n) {
// Base case: If there are no more steps left, we found one way!
if (n == 0) return 1;
// Base case: If there are negative steps left, there's no valid way.
if (n < 0) return 0;
// Recursive case: Count ways by taking one step or two steps.
return countWays(n - 1) + countWays(n - 2);
}
With iteration
int countWays(int n) {
if (n == 0) return 1;
if (n < 0) return 0;
int a = 1, b = 0, temp;
for (int i = 1; i <= n; ++i) {
temp = a;
a = a + b;
b = temp;
}
return a;
}
The Anatomy of a Recursive Function
A successful recursive function must have two essential parts:
- Base Case(s): A condition where the function stops calling itself and returns a value directly. These cases prevent infinite loops and provide concrete solutions for the smallest possible sub-problems.
- Recursive Case(s): A condition where the function calls itself with modified arguments to solve smaller instances of the problem.
Let's dissect our countWays function to see these parts in action:
-
Base Cases:
if (n == 0) return 1;: If there are no more steps left, we found one way.if (n < 0) return 0;: If there are negative steps left, there's no valid way.
-
Recursive Case:
return countWays(n - 1) + countWays(n - 2);: Count ways by taking one step or two steps. Notice how the problem size decreases with each call!
Recursion vs. Iteration
Recursion and iteration (loops) can often be used interchangeably to solve problems. While recursion may provide a more elegant and intuitive solution, it can also lead to performance issues if not implemented carefully.
In some cases, recursion may cause a significant amount of overhead due to function calls, resulting in a slower solution compared to an iterative approach. However, this can often be mitigated through optimization techniques like memoization.
Pointers and References
Pointers and references are a fundamental concept in C++ programming, and they play a crucial role in understanding how memory works within the language. Although pointers may seem intimidating at first, they are essential for writing efficient and flexible code.
Pointer Basics
Pointers are a fundamental concept in C++ and they allow us to access memory directly. They can be a bit confusing at first, but once you understand the basics, they become an invaluable tool in your programming toolbox.
What is a Pointer?
A pointer is a variable that stores the memory address of another variable. In other words, it "points" to the location of another variable in memory. You can think of a pointer as an arrow that points to a specific memory location.
Let's use an analogy to help visualize this concept. Imagine you have several boxes lined up, each containing a piece of data (a number or a character). Each box has its own unique address, just like houses on a street. A pointer is like giving someone directions to one of these boxes by telling them the box's address.
int* ptr;
This declares a pointer ptr that will point to an integer variable (int). The asterisk (*) before the variable name indicates that it's a pointer.
How to Use Pointers
To use pointers effectively, we need to understand two important operators: the address-of operator (&) and the dereference operator (*).
Address-of Operator (&)
int number = 42;
int* ptr = &number;
In this code snippet, we create an integer variable number and assign it the value 42. We then create an integer pointer ptr and assign it the address of number. Now, our pointer ptr is pointing to the memory location where number is stored.
Dereference Operator (*)
The dereference operator (*) allows you to access or modify the value stored at the memory address pointed to by a pointer. For example:
#include <iostream>
int main() {
int number = 42;
int* ptr = &number;
std::cout << *ptr; // Output: 42
return 0;
}
In this example, when we use *ptr, we are essentially saying, "give me the value stored at the address that ptr is pointing to." Since ptr is pointing to number, using *ptr gives us the value of number.
Combining these operators.
To access memory by using its pointer, you can use both the dereference operator and the address-of operator.
You can also modify the value stored at the memory location by using the dereference operator
#include <iostream>
int main() {
int number = 42;
int* ptr = &number;
*ptr = 10;
std::cout << number; // Output: 10
return 0;
}
In this case, we used *ptr to change the value of number indirectly through its memory address.
We are not modifying ptr itself, rather the value it points to.
Conclusion
Pointers are a powerful feature in C++ that allows for direct manipulation of memory addresses. They can be tricky at first but understanding how pointers work will help you write more efficient and flexible programs. Remember these key concepts:
- Pointers store memory addresses.
- Use the address-of operator (
&) to get a variable's memory address. - Use the dereference operator (
*) to access or modify the value at a memory address.
Arrays and Pointers
In C++, arrays and pointers are closely related, as they both deal with memory addresses. An array is a contiguous block of memory that stores multiple elements of the same data type, while a pointer is a variable that holds the address of another variable or an array element.
Iterating through arrays
In C++, sizeof(arr) / sizeof(arr[0]) is a common method to calculate the number of elements in an array.
sizeof(arr) returns the total size (in bytes) of the array, while sizeof(arr[0]) returns the size (in bytes) of a single element in the array.
By dividing the total size of the array by the size of a single element, you can obtain the number of elements in that array.
In C++, you can iterate through an arbitrary sized array using a for loop:
#include <iostream>
int main() {
int arr[] = {1, 2, 3, 4, 5};
int size = sizeof(arr) / sizeof(arr[0]); // Calculate the size of the array
for (int i = 0; i < size; ++i) {
std::cout << arr[i] << " ";
}
return 0;
}
Relationship between Arrays and Pointers
Let's assume we have an integer array arr:
int arr[5] = {1, 2, 3, 4, 5};
The name of the array arr itself points to the base address (i.e., starting address) of the array. This means that you can use a pointer to access the elements of this array.
To understand this better, consider an analogy where each element in the array is a room in a hotel. The hotel represents our memory, and each room (element) has its own unique room number (memory address). The name arr acts like the hotel's entrance - it tells us where the first room starts.
Now let's create an integer pointer p and assign it the base address of our arr.
int* p = arr;
Here, we created a pointer p that points to the first element (room) in our array (hotel). Now we can use this pointer to access individual elements in the array just like using an index
Full Example
#include <iostream>
int main() {
int arr[5] = {1, 2, 3, 4, 5};
int* p = arr;
std::cout << "First element: " << *p << std::endl; // Output: First element: 1
std::cout << "Second element: " << *(p + 1) << std::endl; // Output: Second element: 2
return 0;
}
Notice how we used arithmetic operations on pointers (+1 for accessing next element). This brings us to our next topic, Pointer Arithmetic
Pointer Arithmetic
Pointer arithmetic allows you to perform operations on pointers to manipulate memory addresses directly. Although it may seem complicated at first, understanding the basics of pointer arithmetic can greatly improve your ability to work with arrays and memory in C++. In this section, we will discuss the basics of pointer arithmetic and provide some examples to help you understand the concept.
What is Pointer Arithmetic?
In simple terms, pointer arithmetic is performing mathematical operations (addition or subtraction) on pointers. When you perform these operations on pointers, you're effectively changing the memory address the pointer points to.
Let's use an analogy to better understand this concept: Imagine that a street has houses numbered sequentially (e.g., 1001, 1002, 1003...). If you're standing in front of house number 1001 and take one step forward (pointer + 1), you'll be in front of house number 1002; if you take one step back (pointer - 1), you'll be back at house number 1000.
Similarly, when we add or subtract from a pointer, we're moving forward or backward in memory addresses.
It's important to note that when performing pointer arithmetic, adding or subtracting a value n from a pointer will actually change its address by n * sizeof(type) bytes. This means that if your pointer is pointing to an integer (int*), and sizeof(int) is typically 4 bytes, adding 1 will increase the address by 4 bytes.
Basic Pointer Arithmetic Operations
Here are some basic operations with examples:
Addition
You can add an integer value to a pointer:
int arr[] = {10, 20, 30};
int* ptr = arr; // Pointing to the first element of arr
ptr = ptr + 2; // Now pointing to the third element of arr (arr[2])
Subtraction
You can subtract an integer value from a pointer:
int arr[] = {10, 20, 30};
int* ptr = arr + 2; // Pointing to the third element of arr
ptr = ptr - 1; // Now pointing to the second element of arr (arr[1])
Pointer Difference
You can find the difference between two pointers of the same type:
int arr[] = {10, 20, 30};
int* start_ptr = &arr[0]; // Pointing to the first element of arr
int* end_ptr = &arr[2]; // Pointing to the third element of arr
ptrdiff_t diff = end_ptr - start_ptr; // diff is now equal to 2
ptrdiff_t type is a base signed integer type of C/C++ language. The type's size is chosen so that it could store the maximum size of a theoretically possible array of any type. On a 32-bit system ptrdiff_t will take 32 bits, on a 64-bit one 64 bits.
Pointers are integers and their sizes depend on your system, similarly, ptrdiff_t's size also depends on your system.
Why Use Pointer Arithmetic?
One common use case for pointer arithmetic is working with arrays. Since an array in C++ is stored as a contiguous block of memory, you can use pointer arithmetic to iterate through it and access its elements more efficiently than using indexing.
#include <iostream>
int main() {
int arr[] = {10, 20, 30};
int* ptr;
for (ptr = &arr[0]; ptr != &arr[3]; ++ptr) {
std::cout << *ptr << " ";
}
return 0;
}
In this example, we initialize ptr with the address of the first element in arr. Then, we loop until ptr reaches one past the last element (&arr[3]). Inside the loop, we print out each element by dereferencing ptr.
Understanding and utilizing pointer arithmetic in your programs will help you manage memory more effectively and write efficient code when dealing with arrays or other data structures.
References
References are a convenient feature that allows us to create an alias for a variable. In simple terms, you can think of a reference as another name for an existing variable. When we declare a reference, it must be initialized with a variable, and once initialized, we cannot change the reference to refer to another variable.
Why use references?
References provide an alternative to pointers when working with variables indirectly. Unlike pointers, references are safer because they cannot be nullptr and always refer to a valid object or variable. Additionally, the syntax for using references is cleaner and easier to read compared to pointers.
Here’s an analogy that might help you understand the concept of references better: Imagine you have two names (say "Alice" and "Bob") which both refer to the same person. If someone asks you about Alice or Bob's age, it doesn't matter which name they use because they're referring to the same person. Similarly, in C++, if you have a variable x and its reference y, both can be used interchangeably while accessing or modifying data as they point to the same memory location.
How do we declare and use references?
To declare a reference, put an ampersand (&) before the reference name during declaration followed by equal sign (=) and then mention the variable whose alias it will be:
int x = 42;
int& y = x; // y is now referencing x
Now y is a reference (alias) for x. Any operation we perform on y will affect x
#include <iostream>
int main() {
int x = 42;
int& y = x; // y is now referencing x
y = 10; // This assigns 10 to x through y.
std::cout << "Value of x: " << x << std::endl; // Output: Value of x: 10
std::cout << "Value of y: " << y << std::endl; // Output: Value of y: 10
return 0;
}
References as function arguments
One common use case for references is in function arguments. By passing a reference to a function, we can modify the original variable directly without the need for pointers or returning a new value.
#include <iostream>
void increment(int& num) {
// This increments the variable that was passed in as an argument, not a copy.
num++;
}
int main() {
int x = 5;
increment(x); // Pass x by reference to the increment function.
std::cout << "Value of x after increment: " << x << std::endl; // Output: Value of x after increment: 6
return 0;
}
In this example, we pass x by reference to the increment function. Since it's passed by reference, any changes made inside the increment function will affect our original variable x.
Try removing the reference in increment's argument list, instead of passing by reference this will pass by copy and the original value will not be changed.
Remember that references must be initialized when declared and cannot be changed to refer to another object later. In other words, a reference always refers to the object with which it was initialized.
Data Structures
Data structures are specialized formats for efficiently organizing, storing, and managing data. They allow us to perform a variety of data operations such as insertion, deletion, searching, and sorting. Understanding and selecting the appropriate data structure for a given task can greatly improve the performance of your programs. This section will go over some of the most important data structures in C++.
Multi-Dimensional Arrays
In C++, multi-dimensional arrays are basically arrays of arrays. They are used to hold structured data, such as a table with rows and columns. A common example is an array that depicts a matrix, with multiple rows and columns of data.
Two-Dimensional Arrays
The two-dimensional array (2D array) is the most simple type of multi-dimensional array. Consider it a grid or a table with rows and sections. You must indicate the number of rows and columns when declaring a 2D array:
int myArray[3][4]; // This declares an integer 2D array with 3 rows and 4 columns
Each element in the 2D array can be accessed using its row and column index:
myArray[0][0] = 1; // This sets the first row, first column element to the value 1
You can also initialize a 2D array when declaring it:
// This initializes the elements of our 2D array
int myArray[3][4] = {
{1, 2, 3, 4},
{5, 6, 7, 8},
{9, 10, 11, 12}
};
Multi-Dimensional Arrays
C++ allows you to declare arrays with more than two dimensions by simply adding more square brackets [].
int my3dArray[2][3][4];
This declares an integer 3D array with dimensions
- "depth" or "layers" (size:
2) - "rows" (size:
3) - "columns" (size:
4)
A 3D array can be thought of as a collection of tables or matrices. In this case, we have two layers, each with a table with three rows and four columns.
Just like with 2D arrays, you can access and modify the elements using their indices:
// This sets the first layer, second row, third column element to the value 42
my3dArray[0][1][2] = 42;
You can initialize a multi-dimensional array when declaring it:
// This initializes the elements of 3D array
int my3dArray[2][3][4] = {
{
{1, 2, 3, 4},
{5, 6, 7, 8},
{9, 10, 11, 12}
},
{
{13, 14, 15, 16},
{17, 18, 19, 20},
{21, 22, 23, 24}
}
};
Looping over Multi-Dimensional Arrays
To iterate over all elements in a multi-dimensional array, you can use nested loops. The outer loop iterates over one dimension (e.g., rows), while an inner loop iterates over another (e.g., columns)
#include <iostream>
int main() {
// Print all elements in a given two-dimensional integer array:
int myArray[3][4] = {
{1, 2, 3, 4},
{5, 6, 7, 8},
{9, 10, 11, 12}
};
for (int i = 0; i < 3; ++i) {
for (int j = 0; j < 4; ++j) {
std::cout << "Element at [" << i << "][" << j << "] is: " << myArray[i][j] << std::endl;
}
}
}
The same concept applies to arrays with more dimensions, simply add more nested loops as needed.
Conclusion
Multi-dimensional arrays make it easy to work with structured data in C++. Using indices and loops, they are simple to access and manipulate. However, larger arrays may consume significant memory resources, so when working with multi-dimensional arrays, it is important to consider the size and efficiency.
Intro to Classes and Methods
Classes will not fully be described here but other sections in the Data Structures chapter will be better understood. This will be fully explained in a future chapter.
Introduction to Classes
In C++, a class is a user-defined data type that groups variables (known as attributes) and functions (called methods) under a single name. It serves as a blueprint for creating objects, which are instances of the class.
Think of a class like a template for a cookie-cutter: you can create many cookies (objects) with the same shape (attributes) and actions (methods).
Attributes
Attributes are variables defined within a class. They represent the properties or actions of an object created from the class. For example, if we have a Car class, some possible attributes could be color, brand, and speed.
Methods
Methods are functions defined within a class. They usually represent actions that can be performed by objects created from the class. Continuing with our Car example, some possible methods could be accelerate(), brake(), and changeGear().
Strings & String Functions
std::string is a powerful class in the C++ Standard Library that represents a sequence of characters. It's an alternative to C-style character arrays (like char[]) and provides many helpful functions for string manipulation.
To use std::string, you need to include the <string> header file:
#include <iostream>
#include <string>
int main() {
std::string hello = "Hello world!";
std::cout << hello << std::endl;
return 0;
}
In C++, custom operators, also known as operator overloading, allow us to define how built-in operators like +, -, *, /, and [] will work with our user-defined types. Simply put, we can create our own implementation of these operators to make them behave the way we want when used with our custom objects.
In the std::string class, you may see custom operators. In the upcoming sections, we will dive deeper into the concept of custom operators and explore how to implement them in various scenarios.
Common String Methods
Length and Capacity
Length or Size: length() or size() returns the number of characters in the string.
#include <iostream>
#include <string>
int main() {
std::string s = "hello";
std::cout << s.length(); // Output: 5
return 0;
}
Empty: empty() returns true if the string has no characters, otherwise false.
#include <iostream>
#include <string>
int main() {
std::string emptyString = "";
if (emptyString.empty()) {
std::cout << "The string is empty!" << std::endl;
}
return 0;
}
Accessing Characters
Indexing characters: at(index) or operator[](index) returns a reference to the character at a given position. Indices start from 0, just like arrays.
#include <iostream>
#include <string>
int main() {
std::string str = "hello";
char first = str.at(0); // 'h'
char second = str.operator[](1); // 'e'
char third = str[2]; // 'l'
std::cout << first << std::endl;
std::cout << second << std::endl;
std::cout << third << std::endl;
return 0;
}
Note: Using an index out of bounds will result in undefined behavior.
Modifying Strings
Appending strings: append(std::string) or operator+=(std::string) appends another string or character to the end of the current string.
#include <iostream>
#include <string>
int main() {
std::string greeting = "Hello ";
greeting.append("world!"); // "Hello world!"
greeting += "! How are you today?"; // "Hello world! How are you today?"
std::cout << greeting << std::endl;
return 0;
}
Inserting characters: insert(pos, std::string) inserts a string or character at a specified position.
#include <iostream>
#include <string>
int main() {
std::string message = "We love C";
message.insert(7, "++"); // "We love C++"
std::cout << message << std::endl;
return 0;
}
Erasing characters: erase(pos, count) Erases count characters from the position pos. If count is not provided, it erases all characters until the end of the string.
#include <iostream>
#include <string>
int main() {
std::string text = "I like bananas";
text.erase(7, 8); // "I like"
std::cout << text << std::endl;
return 0;
}
Searching and Comparing
Finding occurrences: find(std::string) Searches for the first occurrence of a substring and returns its starting position. If not found, it returns the std::string::npos constant (or -1).
#include <iostream>
#include <string>
int main() {
std::string sentence = "C++ is fun!";
size_t pos = sentence.find("fun");
if (pos != std::string::npos) {
std::cout << "Found 'fun' at position: " << pos << std::endl;
}
return 0;
}
Comparing strings: compare(std::string) Compares two strings. Returns 0 if they're equal, a positive value if the first string is greater than the second one, and a negative value otherwise.
#include <iostream>
#include <string>
int main() {
std::string s1 = "apple", s2 = "banana";
int result = s1.compare(s2);
if (result == 0) {
std::cout << "s1 equals s2" << std::endl;
} else if (result > 0) {
std::cout << "s1 is greater than s2" << std::endl;
} else {
std::cout << "s1 is less than s2" << std::endl;
}
return 0;
}
C-style Strings and String Functions
C-style strings are a way to represent character sequences in C++ using arrays of characters. These strings are terminated by a special character called the null terminator (\0). The null terminator indicates the end of the string and is essential for various string manipulation functions.
Declaring C-style Strings
You can declare and initialize a C-style string in several ways:
- Using an array with size specification:
char str[6] = "Hello";
- Without specifying the size, let the compiler determine it:
char str[] = "Hello";
- As a pointer to a constant character sequence (not modifiable):
const char* str = "Hello";
Remember that when declaring an array, one extra space is needed for the null terminator.
Basic String Functions
C++ provides several useful functions for manipulating C-style strings, which are available by including the <cstring> header file.
Here are some common string functions:
strlen(str): returns the length ofstr(excluding the null terminator).strcpy(dest, src): copies the contents ofsrc(including null terminator) intodest.strcat(dest, src): appendssrcat the end ofdest.strcmp(str1, str2): compares two strings lexicographically; returns 0 if equal, <0 ifstr1comes beforestr2, >0 otherwise.
#include <iostream>
#include <cstring>
int main() {
const char* greeting = "Hello";
char name[] = "Alice";
// Calculate lengths
std::cout << "Length of greeting: " << strlen(greeting) << std::endl;
std::cout << "Length of name: " << strlen(name) << std::endl;
// Concatenate strings
char combined[12];
strcpy(combined, greeting);
strcat(combined, ", ");
strcat(combined, name);
std::cout << "Combined: " << combined << std::endl;
// Compare strings
if (strcmp(name, "Alice") == 0) {
std::cout << "Name is Alice" << std::endl;
} else {
std::cout << "Name is not Alice" << std::endl;
}
return 0;
}
String Views
What is std::string_view?
std::string_view is a lightweight, read-only view into a sequence of characters (i.e., a string). It was introduced in C++17 as an efficient way to work with strings without creating copies or modifying the original string. You can think of std::string_view as a window that allows you to look into a string and perform various operations on it without actually making any changes.
Why use std::string_view?
- Performance: Since
std::string_viewdoes not own its data and only provides a view into the underlying string, no memory allocation or deallocation is involved when working with it. This makes it faster than usingstd::stringin many cases. - Flexibility:
std::string_viewcan work with different types of strings like null-terminated C-style strings,std::string, or even custom string classes. - Read-only: As
std::string_viewis read-only, it ensures that the original string remains unmodified during operations. This allows it to cache it's length instead of callingstrlenrepeatedly.
How to use std::string_view?
To use std::string_view, you need to include the <string_view> header:
#include <iostream>
#include <string>
#include <string_view>
int main() {
std::string myString = "Hello, World!";
std::string_view myStringView(myString);
// Print both the original string and the string view
std::cout << "Original String: " << myString << std::endl;
std::cout << "String View: " << myStringView << std::endl;
return 0;
}
In this example, we create a std::string, and then create a std::string_view that refers to the same sequence of characters. When we print both the original string and the string view, they display the same content.
Using std::string_view with functions
You can use std::string_view as an parameter in a function that works with strings. This makes your code more efficient and flexible
#include <iostream>
#include <string>
#include <string_view>
// Function that takes a std::string_view an argument.
void printLength(std::string_view str) {
std::cout << "Length of '" << str << "' is: " << str.length() << std::endl;
}
int main() {
std::string myString = "Hello, World!";
const char* myCString = "Hello, C++!";
// Call the function with different types of strings
printLength(myString);
printLength(myCString);
printLength("This is a literal");
return 0;
}
In this example, we define a function print_length() that accepts a std::string_view and prints its length. We then call this function using both std::string and a C-style string (null-terminated character array). The output shows the correct length for both types of strings without owning or copying the memory holding the string's data.
Remember that since std::string_view is read-only, you should not use it if you need to modify the string or if you need to store it beyond the lifetime of the original string. In those cases, you should stick to using std::string. Primarily, std::string_view is used for consuming the content of a string (eg. string arguments). However, it also plays a crucial role in manipulating the string's view by performing complex substring-like operations. This becomes particularly relevant in parsing tasks where expensive string operations are carried out, such as removing prefixes or utilizing indices. By using std::string_view, one can efficiently abstract these calculations without creating new strings in the process.
Vectors
Vectors are a powerful data structure provided by the C++ Standard Library. They can be thought of as dynamic arrays, allowing you to store elements in a linear fashion while offering the ability to easily resize them during runtime.
Why Use Vectors?
Imagine you have a collection of items (e.g., grades of students) that needs to be stored in memory. You could use an array, but arrays have a fixed size, which means you need to know the number of elements beforehand. What if you don't know how many elements there will be? This is where vectors come into play. They automatically manage their size and can grow or shrink as needed.
Some advantages of using vectors over built-in arrays:
- Dynamic resizing
- Bounds checking (avoiding buffer overflows)
- Easy insertion and removal of elements
Buffer overflows are a type of programming error that occurs when a program writes more data to a fixed-size buffer (usually an array) than it can hold. This excess data may "overflow" into the adjacent memory locations, causing unintended consequences such as data corruption, application crashes, or even security vulnerabilities.
In C and C++, buffer overflows often result from unsafe operations on arrays or pointers without proper bounds checking. When the program attempts to write beyond the allocated space for the buffer, it may overwrite other important data in memory.
Basic Usage
To use vectors in your program, first include the <vector> header:
#include <vector>
Now you can create a vector by specifying its type within angle brackets <>:
std::vector<int> intVector;
This creates an empty vector capable of storing integers.
Adding Elements
You can add elements to the end of the vector using the push_back() method:
intVector.push_back(42);
Accessing Elements
To access an element at a specific index, use the [] operator, just like with arrays:
int value = intVector[0]; // Accesses the first element.
Keep in mind that accessing an out-of-bounds index results in undefined behavior. To avoid this, use the at() method which throws an exception if the index is invalid
#include <iostream>
#include <vector>
int main() {
std::vector<int> intVector;
try {
int value = intVector.at(5); // Throws std::out_of_range if index is invalid.
} catch (const std::out_of_range& e) {
std::cerr << "Invalid index: " << e.what() << std::endl;
}
return 0;
}
Exceptions will be explained in a later section. All you need to know for now is when an exception is "thrown" or "raised" in a try block it needs to be caught with catch as shown above.
Removing Elements
You can remove the last element of a vector by calling pop_back():
intVector.pop_back();
Vector Size
To get the number of elements in a vector, use the size() method:
size_t size = intVector.size(); // Returns the number of elements.
Example: Storing and Displaying Grades
#include <iostream>
#include <vector>
int main() {
std::vector<int> grades;
// Add some grades to the vector
grades.push_back(85);
grades.push_back(90);
grades.push_back(78);
// Print out all the grades
for (int i = 0; i < grades.size(); ++i) {
std::cout << "Grade " << i+1 << ": " << grades[i] << std::endl;
}
return 0;
}
In this example, we created a vector to store integer values representing student grades. We then added three sample grades using push_back() and printed them using a standard loop.
Remember that vectors are just one type of data structure, but they offer several advantages over built-in arrays.
Maps
TODO
Iterators
Iterators allow us to access and navigate through elements in various container classes, such as arrays, vectors, and maps. You can think of an iterator as a cursor that points to an element within a container, allowing you to access its value or even modify it.
Basic Usage
The most common way to use iterators is with loops. Let's say we have a vector of integers and want to print each element:
#include <iostream>
#include <vector>
int main() {
std::vector<int> numbers = {1, 2, 3, 4, 5};
for (std::vector<int>::iterator it = numbers.begin(); it != numbers.end(); ++it) {
std::cout << *it << " ";
}
return 0;
}
Here we are using an iterator it of type std::vector<int>. We initialize the iterator with numbers.begin() which returns an iterator pointing to the first element in the vector. The loop then continues until the iterator reaches numbers.end(), which represents one past the last element of the vector. You can also do this with a range based for loop.
Inside the loop body, we use *it (dereference operator) to access the value pointed by the iterator. This prints out each integer separated by a space: 1 2 3 4 5.
C++11 introduced the auto keyword which allows us to simplify our code by automatically deducing variable types based on their return type.
#include <iostream>
#include <vector>
int main() {
std::vector<int> numbers = {1, 2, 3, 4, 5};
for (auto it = numbers.begin(); it != numbers.end(); ++it) {
std::cout << *it << " ";
}
return 0;
}
Conclusion
Iterators provide a consistent way to interface with different container types while maintaining code readability and simplicity. They are not limited to vectors and can be used with other containers which we will explain in future sections.
Object-Oriented Programming (OOP)
Object-oriented programming (OOP) is a programming paradigm (design) that uses "objects" to design and build applications. An object is a combination of data (attributes) and functions (methods) that can manipulate the data.
In this section, we will briefly introduce OOP concepts and provide simple examples to help you get started with OOP.
- Classes and Objects
- Constructors and Destructors
- Inheritance
- Polymorphism
- Encapsulation and Abstraction
- Templates
Classes and Objects
Classes and objects are the fundamental building blocks for object-oriented programming. A class is like a blueprint, which defines attributes (members) and behaviors (methods) for creating objects. An object is an instance of a class, which represents a specific entity with its own set of attributes and behaviors.
Class
A class can be seen as a template or blueprint that defines the structure and behavior of objects created from it. You can think of a class as a cookie cutter and objects as the individual cookies made using that cutter.
To define a class, we use the class keyword followed by the name of the class, then enclose the definition within curly braces {}.
class Person {
public:
// Members (attributes)
std::string name;
int age;
// Methods (behaviors)
void introduce() {
std::cout << "Hello, my name is " << name << " and I am " << age << " years old." << std::endl;
}
};
Object
The this keyword in C++ classes is a special pointer that points to the object for which a member function is called. It's used inside a class's methods to reference the current object instance itself.
An object is an instance of a class. It has its own state (values for its data members) and can perform actions defined by its member functions. We can create multiple objects from one class, each with different attribute values.
To create an object from a class, we simply declare it just like any other variable type followed by the object's name:
Person person1;
We can now access this object's data members and member functions using the dot operator (.):
person1.name = "John";
person1.age = 25;
person1.introduce();
#include <iostream>
#include <string>
class Person {
public:
// Members (attributes)
std::string name;
int age;
// Methods (behaviors)
void introduce() {
std::cout << "Hello, my name is " << this->name << " and I am " << this->age << " years old." << std::endl;
}
};
int main() {
// Create an object of the Person class
Person person1;
// Set the values for the data members
person1.name = "John";
person1.age = 25;
// Call the member function using the object
person1.introduce();
return 0;
}
In this example, we defined a Person class with two members (name and age) and one method (introduce). We then created an object person1, set its attributes, and called its introduce method.
Public and Private Access Modifiers
To control access to our members and methods, we use access modifiers - public, private, and protected. In this section, we'll focus on public and private.
Public Members
Public members are accessible from any part of the code that can access the object of a class. They are declared using the keyword public. Think of them as the "open" parts of a class that everyone can see and use.
Private Members
Private members can only be accessed from within the same class. They cannot be accessed from outside the class or derived classes. They are declared using the keyword private. You can think of private members like a secret recipe hidden inside a chef's cookbook that only they can see.
#include <iostream>
class Circle {
public:
void setRadius(double r) {
radius = r;
}
double getArea() {
return 3.14159 * radius * radius;
}
private:
double radius;
};
int main() {
Circle myCircle;
// Accessing public member function setRadius()
myCircle.setRadius(5);
// Accessing public member function getArea()
std::cout << "The area of circle is: " << myCircle.getArea() << std::endl;
// The following line will cause an error because 'radius' is private.
// Try uncommenting it and running it.
// std::cout << "The radius of circle is: " << myCircle.radius << std::endl;
return 0;
}
Arrow Operator (->) vs Dot Operator (.)
In C++, we use the dot operator . to access members of an object and the arrow operator -> to access members of an object through a pointer. The arrow operator is essentially a shorthand for dereferencing a pointer and then using the dot operator.
When to Use Arrow Operator
You would use the arrow operator when you have a pointer to an object, rather than an actual object. This is quite common in situations where memory management or object manipulation through pointers is required.
#include <iostream>
#include <string>
class Person {
public:
// Members (attributes)
std::string name;
int age;
// Methods (behaviors)
void introduce() {
std::cout << "Hello, my name is " << this->name << " and I am " << this->age << " years old." << std::endl;
}
};
int main() {
// Create an object of the Person class
Person person1;
// Set the values for the members
person1.name = "John";
person1.age = 25;
// Call the method using the dot operator
person1.introduce();
// Create a pointer to the Person class
Person* ptrPerson = &person1;
// Access members and methods using arrow operator "->"
ptrPerson->name = "Jane";
ptrPerson->age = 30;
ptrPerson->introduce();
return 0;
}
Constructors and Destructors
Constructors and destructors are special methods of a class that are automatically called when an object is created or deleted. They allow you to initialize the object's attributes and perform clean-up tasks.
Constructors
A constructor is a member function of a class with the same name as the class, which is used to initialize the object's attributes when it is created. It does not have any return type, not even void. You can think of constructors as "blueprints" that guide how objects should be set up initially.
Constructors can be overloaded by specifying different numbers or types of parameters. However, if you do not define any constructor in your class, the compiler will automatically provide a default constructor with no parameters.
#include <iostream>
class House {
public:
std::string color;
// Default constructor
House() {
this->color = "Blue";
}
// Parameterized constructor
House(std::string color) {
this->color = color;
}
void printColor() {
std::cout << "This house is: " << color << std::endl;
}
};
int main() {
House house1;
House house2("Red"); // Calls parameterized constructor
house1.printColor();
house2.printColor();
return 0;
}
In this example, we have defined two constructors for the House class: one without parameters (default) and another one with two parameters. When we create objects house1 and house2, each calls a different constructor based on the provided arguments.
Destructors
A destructor is another special member function of a class that gets automatically called when an object goes out of scope or is explicitly deleted. It also has the same name as the class, but it is preceded by a tilde ~. Destructors are used to perform clean-up tasks, such as releasing memory or closing files.
Unlike constructors, destructors cannot be overloaded and you can have only one destructor per class.
#include <iostream>
class House {
public:
std::string color;
// Default constructor
House() {
this->color = "Blue";
}
// Parameterized constructor
House(std::string color) {
this->color = color;
}
~House() {
std::cout << color << " house has been destroyed" << std::endl;
}
void printColor() {
std::cout << "This house is: " << color << std::endl;
}
};
int main() {
{
House house1;
house1.printColor();
// Do stuff here...
} // Destructor called when going out of scope.
return 0;
}
In this example, we defined a destructor for the House class. When the object house1 goes out of scope (at the end of the inner block), its destructor is automatically called.
Initializer Lists
Initializer lists are used to initialize member variables before the body of the constructor is executed. They can improve performance by preventing unnecessary default initialization and assignment operations.
You can use initializer lists in constructors by appending them after the colon : and before the opening brace {.
class Dog {
public:
std::string name;
int age;
// Constructor with initializer list
Dog(std::string n, int a) : name(n), age(a) {}
};
In this example, we use an initializer list in the Dog constructor to directly initialize name and age without requiring any additional assignment statements.
Copy Constructors
A copy constructor is a special type of constructor used to create a new object as a copy of an existing one. It takes a reference to the same class as its parameter.
If you don't define a copy constructor, the compiler will generate one automatically for you. However, sometimes you may need to define your own custom copy constructor.
#include <iostream>
class Dog {
public:
std::string name;
int age;
// Default constructor
Dog(std::string n, int a) : name(n), age(a) {}
// Copy constructor
Dog(const Dog& other) {
name = other.name;
age = other.age;
std::cout << "A dog named " << name << " has been cloned!" << std::endl;
}
};
int main() {
Dog dog1("Fido", 3);
Dog dog2(dog1); // Calls copy constructor
return 0;
}
Deleting Constructors
In some cases, you might want to prevent certain types of constructors from being generated by the compiler. For instance, if you want to prevent a class from being copied, you can delete the copy constructor and assignment operator.
#include <string>
class Dog {
public:
std::string name;
int age;
// Default constructor
Dog(std::string n, int a) : name(n), age(a) {}
// Delete copy constructor and assignment operator
Dog(const Dog&) = delete;
Dog& operator=(const Dog&) = delete;
};
int main() {
Dog dog1("Fido", 3);
// The following lines (each) will cause a compile-time error.
Dog dog2(dog1);
Dog dog3 = dog1;
return 0;
}
In this example, we've deleted the copy constructor and assignment operator for the Dog class. This will prevent instances of this class from being copied or assigned to one another.
Header files
In C++, it is common practice to separate class declarations from their definitions. This is done using header files (with the .h or .hpp extension) for declarations and source files (with the .cpp extension) for definitions.
However, to keep things simple in this guide, we will declare and define our classes within a single file. Although this is not recommended for large projects, it's perfectly fine when learning or working on small programs.
Car.hpp#include <string> class Car { public: Car(const std::string& brand, int year); void honk(); private: std::string brand; int year; };
Car.cpp#include "Car.hpp" #include <iostream> Car::Car(const std::string& brand, int year) : brand(brand), year(year) {} void Car::honk() { std::cout << "Honk! I'm a " << brand << " car from " << year << ".\n"; }
In this guide, we will continue to declare and define classes within the same file for simplicity. However, keep in mind that it is good practice to separate them as shown above when working on real-world projects.
Inheritance
Inheritance is a fundamental concept in object-oriented programming (OOP) that allows you to create a new class (called the derived class) from an existing class (called the base class). The derived class inherits properties and behavior from the base class, allowing you to reuse code and model real-world relationships between objects.
The protected keyword is one of the access specifiers used in C++ to control the visibility and accessibility of class members (variables, methods, etc.). It lies between public and private access specifiers in terms of accessibility. A protected member can be accessed within its own class and inherited classes (derived from it).
Imagine a simple example with animals. All animals share some common characteristics like eating, sleeping, and moving. So, we can create a base class called Animal that contains these common behaviors. Then, if we want to create specific animal classes like Dog or Cat, they can inherit from the Animal class and automatically have those common behaviors without needing to redefine them.
#include <iostream>
// Base class
class Animal {
public:
void eat() {
std::cout << "I can eat!" << std::endl;
}
void sleep() {
std::cout << "I can sleep!" << std::endl;
}
};
// Derived class
class Dog : public Animal {
public:
void bark() {
std::cout << "I can bark! Woof woof!" << std::endl;
}
};
int main() {
Dog dog1;
// Calling base class function using derived class object
dog1.eat();
dog1.sleep();
// Calling derived class function
dog1.bark();
return 0;
}
This example demonstrates how the Dog derived class inherits the eat() and sleep() functions from the Animal base class. You don't need to define these functions again in the Dog class; they are automatically available through inheritance.
The public keyword is used before specifying the base class (Animal). This indicates how members of the base class are accessible in the derived class. There are three access specifiers:
public: Base class's public and protected members become public in the derived class.protected: Base class's public and protected members become protected in the derived class.private(default if not specified): Base class's public and protected members become private in the derived class.
Overriding Methods in C++
In C++, method overriding is a feature that allows a derived class (child class) to provide a new implementation for an existing method declared in its base class (parent class). This concept is crucial when it comes to achieving polymorphism - one of the four fundamental principles of object-oriented programming.
How to Override Methods
To override a method, simply declare and define it with the same name and parameters as in the base class but with different functionality inside the derived class.
#include <iostream>
// Base Class
class Animal {
public:
void speak() {
std::cout << "The animal makes a sound" << std::endl;
}
};
// Derived Class
class Dog : public Animal {
public:
// Override speak() function
void speak() {
std::cout << "The dog barks" << std::endl;
}
};
int main() {
Dog myDog;
myDog.speak(); // Output: The dog barks
return 0;
}
Multiple Inheritances
Multiple inheritance is a feature that allows a class to inherit properties and behaviors from more than one parent class. In other words, a derived class can have multiple base classes. This concept is quite similar to how an individual can inherit traits from both their mother and father.
Basic Syntax
The syntax for multiple inheritance is quite simple; you just need to separate the base classes with commas while declaring the derived class.
class DerivedClass: public BaseClass1, public BaseClass2 {
// Class body
};
In this example, DerivedClass inherits from both BaseClass1 and BaseClass2.
Example
Let's create a simple program to demonstrate multiple inheritance. Suppose we want to model animals in our program, specifically birds and mammals. We'll create two base classes (Bird and Mammal) and then create a derived class called Bat, which is both a bird (it can fly) and a mammal (it feeds its young with milk).
NOTE: Bats are not actually birds, this is just an example.
#include <iostream>
// Base class Bird
class Bird {
public:
void canFly() {
std::cout << "I can fly." << std::endl;
}
};
// Base class Mammal
class Mammal {
public:
void canFeedMilk() {
std::cout << "I can feed milk." << std::endl;
}
};
// Derived class Bat inheriting from Bird and Mammal
class Bat: public Bird, public Mammal {
};
int main() {
Bat bat;
// Calling methods inherited from both base classes
bat.canFly();
bat.canFeedMilk();
return 0;
}
As you can see, the Bat class inherited methods from both Bird and Mammal.
Ambiguity in Multiple Inheritance
One issue that may arise with multiple inheritance is ambiguity when two or more base classes have methods with the same name. In such cases, the compiler won't know which method to call from the derived class object.
#include <iostream>
// Base class A
class A {
public:
void display() {
std::cout << "Base class A" << std::endl;
}
};
// Base class B
class B {
public:
void display() {
std::cout << "Base class B" << std::endl;
}
};
// Derived class C inheriting from A and B
class C: public A, public B {
};
int main() {
C c;
// This line will cause a compilation error due to ambiguity
c.display();
return 0;
}
Resolving the ambiguity
To resolve this ambiguity, you can use scope resolution operator :: while calling the method to specify which base class method should be called:
c.A::display(); // Calls display() method of base class A
c.B::display(); // Calls display() method of base class B
By using the scope resolution operator in our previous example, we can now call both display() methods without any ambiguity.
Multilevel Inheritance
Multilevel inheritance is a concept in OOP where a class inherits from another class, which is itself a derived class of some other base class. It allows us to create new classes that share characteristics and behavior of multiple parent classes, following the "is-a" relationship.
In simple words, imagine multilevel inheritance as a family tree - just like how you inherit properties from both your parents and grandparents.
Simple Multilevel Inheritance
Let's consider an example where we have three classes: Animal, Mammal, and Dog. The Animal class is our base (top-level) class, followed by the Mammal derived class, and finally, the Dog derived class at the bottom level.
classDiagram
direction LR
Dog --> Mammal : Inherits
Mammal --> Animal : Inherits
class Animal {
+eat()
}
class Mammal {
+giveBirth()
}
class Dog {
+bark()
}
#include <iostream>
// Base Class
class Animal {
public:
void eat() {
std::cout << "Eating..." << std::endl;
}
};
// Derived Class 1
class Mammal : public Animal {
public:
void giveBirth() {
std::cout << "Giving birth..." << std::endl;
}
};
// Derived Class 2
class Dog : public Mammal {
public:
void bark() {
std::cout << "Barking..." << std::endl;
}
};
int main() {
Dog dog;
dog.eat(); // Inherited from Animal class
dog.giveBirth(); // Inherited from Mammal class
dog.bark(); // Member of Dog class
return 0;
}
In this example, the Dog class inherits properties and behavior from both Animal and Mammal classes through multilevel inheritance.
Multilevel Inheritance with Constructors
Let's consider another example where we have three classes: Person, Employee, and Manager. The constructors in each class will help us understand the order of execution during object instantiation.
#include <iostream>
// Base Class
class Person {
public:
Person() {
std::cout << "Constructor of Person" << std::endl;
}
};
// Derived Class 1
class Employee : public Person {
public:
Employee(std::string_view company) {
std::cout << "Constructor of Employee for Company: " << company << std::endl;
}
};
// Derived Class 2
class Manager : public Employee {
public:
Manager() : Employee("Apple") {
std::cout << "Constructor of Manager" << std::endl;
}
};
int main() {
Manager manager; // Instantiate an object of Manager class
return 0;
}
In this example, the order in which constructors are called follows the hierarchy from top to bottom. The base class constructor is called first (Person), followed by the derived class constructors (Employee and then Manager). Also note how you would call a constructor with arguments for a base class.
Polymorphism
The term Polymorphism is derived from Greek words where 'Poly' means many and 'morphism' means forms. Hence, polymorphism represents the ability to take many forms.
In C++, polymorphism causes a member function to behave differently based on its calling object. This ability is achieved through method overloading, operator overloading, and virtual functions.
Method Overloading
Method Overloading is a type of static or compile-time polymorphism. It allows multiple functions with the same name but different parameters, to be defined within the same scope. When you call an overloaded function, the compiler determines the most appropriate function to execute by examining the number, types and order of the arguments.
Method overloading differs from a function. Overloaded methods must reside within the same class.
Here is how we achieve method overloading
#include <iostream>
class Rectangle {
public:
// Method with no parameters
void display() {
std::cout << "Displaying Rectangle" << std::endl;
}
// Method with 1 parameter
void display(int a) {
std::cout << "Displaying Square: " << a << std::endl;
}
// Method with 2 parameters
void display(int a, int b) {
std::cout << "Displaying Rectangle: " << a << " and " << b << std::endl;
}
};
int main() {
Rectangle r;
// Calling the display method without parameters
r.display();
// Calling the display method with 1 parameter
r.display(10);
// Calling the display method with 2 parameters
r.display(10, 5);
return 0;
}
In the above example, the first display() method is called when there are no parameters, the second display(int a) method is called when there is one integer parameter, and the third display(int a, int b) method is called when there are two integer parameters.
This is how method overloading helps to implement polymorphism in C++.
Operator Overloading
Operator overloading is another way of achieving polymorphism in C++. It allows you to redefine or overload most of the built-in operators available in C++. This means that operators can function in a way that is intuitive or makes more sense for a particular class.
When we use an operator on built-in data types, the compiler knows what mathematical operation is meant to be performed. But when we use them for objects, it is not clear what operation to perform unless we define these operations. That's when we overload the operators depending upon our needs.
C++ allows you to specify more than one definition for a function name in the same scope, which is the ability of functions with the same name functioning in different ways.
#include <iostream>
class Complex {
public:
int real, imag;
Complex(int r = 0, int i = 0) {
this->real = r;
this->imag = i;
}
// Overloading the + operator
Complex operator + (Complex const &obj) {
Complex result;
result.real = real + obj.real;
result.imag = imag + obj.imag;
return result;
}
void print() {
std::cout << this->real << " + i" << this->imag << "\n";
}
};
int main() {
Complex c1(10, 5);
Complex c2(2, 4);
// An example call to "operator+"
Complex c3 = c1 + c2;
c3.print();
return 0;
}
In the above example, the + operator is overloaded to perform addition on two objects of Complex class. We return a new object which contains the result, and then we call the print method to display the result.
Operator overloading makes the code more readable and writable, but misuse of it can lead to code that's challenging to understand and debug. It's essential to use it with caution and keep your overloaded operators intuitive and predictable.
Additional Operators that can be Overloaded
Other than the addition operator we discussed earlier, C++ allows overloading of a wide range of operators such as subtraction -, multiplication *, division /, comparison == != < >, increment ++, decrement --, and more. Here is a selection of commonly overloaded operators and their signatures.
Subtraction Operator -
Subtracts one object from another of the same class.
ClassName operator -(const ClassName& rightOperand);
Multiplication Operator *
Multiplies the contents of an object with another of the same class.
ClassName operator *(const ClassName& rightOperand);
Division Operator /
Divides the contents of one object by another of the same class.
ClassName operator /(const ClassName& rightOperand);
Equality Operator ==
Compares one object to another and returns true if they are equal.
bool operator ==(const ClassName& rightOperand);
Inequality Operator !=
Compares one object to another and returns true if they are not equal.
bool operator !=(const ClassName& rightOperand);
Less Than Operator <
Compares one object to another and returns true if the left-hand side object is less than the right-hand side object.
bool operator <(const ClassName& rightOperand);
Greater Than Operator >
Compares one object to another and returns true if the left-hand side object is greater than the right-hand side object.
bool operator >(const ClassName& rightOperand);
Increment Operator ++
Increases the value of an object.
ClassName& operator ++(); // Prefix increment operator
ClassName operator ++(int); // Postfix increment operator
Decrement Operator --
Decreases the value of an object.
ClassName& operator --(); // Prefix decrement operator
ClassName operator --(int); // Postfix decrement operator
Array Subscript Operator []
Accesses a specific object within a collection, such as an array or list.
ClassName& operator [](int index);
The operator receives an index and returns a reference to the object at the specific index in the collection.
Dereference Operator *
Provides a reference to an object when we have a pointer to the object.
ClassName& operator *();
The operator does not take any parameters, but it returns a reference to the object it points to. This allows it to be used in contexts where a reference to the object is required, rather than the pointer itself.
Dot Operator .
Accesses a member of an object.
ClassName& operator .();
This operator is unique because it cannot be overloaded directly in a class. However, it can be effectively "overloaded" via a member function designated to handle its behavior on specific types.
Arrow Operator ->
Accesses a member of an object through a pointer.
ClassName* operator ->();
The operator returns a pointer to a member of the object it points to, allowing it that member to be accessed directly via a pointer to an object instance.
Remember to only overload operators where it makes logical sense in your code and can improve code readability. Overloading operators improperly can cause confusion and create bugs that are hard to trace.
Remember, when overloading operators, always make sure that the overloaded operator behaves in a meaningful way that's intuitive and consistent with the rest of your code. Improper use of operator overloading can lead to code that's confusing and hard to debug.
It should be noted, in C++, the dot operator . and arrow operator -> are not directly overloadable. But we can achieve the effect of overloading the arrow operator with a smart pointer or proxy class, depending upon the context. The behavior of the dot operator can't be directly changed, but can be manipulated indirectly with the user of operator overloading on a returned object.
Here is an example of creating an overloaded arrow operator -> by creating a smart pointer class:
#include <iostream>
class Test {
public:
void func() {
std::cout << "func() called" << std::endl;
}
};
// A Smart Pointer: Overloading operators using Arrow Operator
class SmartPtr {
Test* ptr; // Actual pointer
public:
SmartPtr(Test* p = nullptr) {
ptr = p;
}
// Overloading dereferencing operator
Test& operator *() {
return *ptr;
}
// Overloading arrow operator so that members of Test can be accessed
// like a pointer (useful if Test has public data members)
Test* operator -> () {
return ptr;
}
};
int main() {
SmartPtr ptr(new Test());
ptr->func();
return 0;
}
In the SmartPtr class, we overloaded the arrow operator. When we create an object of this proxy class and access the member function func(), it essentially provides access to the Test class member function, allowing it to be used like the traditional dereference-and-dot (->) operator.
Pipe (Insertion and Extraction) Operators << and >>
In the context of operator overloading, the pipe operators << and >> also play a significant role. These operators are used for sending formatted output to standard output devices, or for receiving formatted input from standard input devices.
Insertion Operator <<
The insertion operator << is a binary operator that is used to output the data. Its left operand is an ostream object (like cout), and the right operand is the value to be output.
ostream& operator << (ostream& out);
Extraction Operator >>
The extraction operator >> also is a binary operator and is essentially the opposite of the insertion operator. It is used to read data from input. Its left operand is an istream object (like cin), and the right operand is where the input will be stored.
istream& operator >> (istream& in);
Examples of overloading these operators are widely seen in standard library implementations, but they can also be overloaded in user defined classes for custom behavior.
You might be wondering how statements like std::cout << "Hello World!" << std::endl; have been functioning in your C++ programs.
The std::cout is an instance of std::ostream and the << operator here is actually an overloaded operator. The std::ostream class that cout is an instance of has member functions for operator<< overloaded for different types like int, float, double, const char* etc. This is what allows us to call cout << variable for variables of different data types.
Then we can chain calls to the << operator because each << operator call returns a reference to cout. So cout << "Hello" << " World!" << std::endl; is equivalent to ((cout << "Hello") << " World!") << std::endl;.
Each call to << returns the cout reference allowing the next << to be called on that reference. This mechanism is known as method chaining.
It's also important to note that the std::endl is a manipulator that writes a newline and flushes the stream.
So, std::cout, <<, and std::endl working in unison give us the intuitive operation that we use so often to print values on the console.
Virtual Functions
A critical characteristic of polymorphism in C++ is achieved through the use of virtual functions. A virtual function is a member function that we expect to be redefined in derived classes. When we refer to a derived class object using a pointer or a reference to the base class, we can call a virtual function for that object and execute the derived class's version of the function. This mechanism is commonly known as "late binding" or "dynamic binding".
Declare a function in the base class as virtual when it is intended to be overridden in any derived class.
#include <iostream>
// Base class
class Base {
public:
virtual void print() {
std::cout << "This is base class print function." << std::endl;
}
};
// Derived class
class Derived : public Base {
public:
void print() override {
std::cout << "This is derived class print function." << std::endl;
}
};
int main() {
Base* basePtr;
Derived derivedObj;
// Point base class pointer to derived class object
basePtr = &derivedObj;
// Call print function using base class pointer
// It calls derived class print function due to virtual function
basePtr->print();
return 0;
}
In the above example, print() function is declared virtual in the base class and overridden in the derived class. When we use a base class pointer pointing to a derived class object and call the print() function, it runs the derived class's print() function. This is because the print() function is declared as virtual in the base class, which generates a late binding.
By marking a method as virtual, we signal the compiler to ensure that the correct method is called according to the actual type of the object, not the type of the pointer or reference that is used to call the function.
This powerful feature allows us to work abstractly with groups of related classes and permits the exact behavior to be determined by the dynamic type of the objects themselves. This is a central concept of many large-scale, OOP designs and frameworks.
Abstract Functions and Polymorphism
An abstract function is a virtual function that we declare in the base class and has no definition relative to the base class. A class containing at least one abstract function also becomes abstract, and you cannot create objects from it.
Let's modify our previous code to demonstrate abstract functions and casting for polymorphism.
#include <iostream>
// Base class
class AbstractBase {
public:
virtual void print() = 0; // Pure virtual function makes this class Abstract class
};
// Derived class
class Derived : public AbstractBase {
public:
void print() override {
std::cout << "This is derived class print function." << std::endl;
}
};
int main() {
// Pointers to abstract class type
AbstractBase* basePtr;
Derived derivedObj;
// Point base class pointer to derived class object
basePtr = &derivedObj;
// Call print function using base class pointer - calls derived class function
basePtr->print();
// Now we use casting and you will see that dynamic binding still applies.
basePtr = static_cast<AbstractBase*>(&derivedObj);
basePtr->print(); // Still prints "This is derived class print function."
return 0;
}
In this example, print() is a pure virtual function (or abstract function) in the AbstractBase class and overridden in the Derived class. We cannot create objects of an abstract class, but we can create pointers of the AbstractBase class type. When this pointer points to a Derived class object, and we call the print() function, it calls the Derived class's print() function, demonstrating the dynamic binding nature of virtual functions.
The casting does not change the dynamic binding. Even after casting the derivedObj into an AbstractBase type pointer, when we call the print() function via the basePtr, the derived class function is called.
C++ Polymorphism allows us to use derived class objects just like their base class, making it easier to write more efficient code.
Encapsulation and Abstraction
Encapsulation
Encapsulation is one of the key characteristics of object-oriented programming. It refers to the bundling of data, and the methods that operate on that data, into a single unit or 'capsule'. This way, the data is not accessed directly; it is accessed through the functions present inside the class. As a result, it provides a layer of security to the data.
Consider the analogy of a pill in which the medicine (data) is encapsulated and is not directly accessible. The coating of the pill (class methods) controls the release of medicine. You cannot take the medicine directly; you must take it through the pill(A pill with a coating that lets it dissolve slowly).
class BankAccount {
private:
int balance;
public:
void deposit(int amount) {
if (amount > 0)
balance += amount;
}
void withdraw(int amount) {
if (amount > 0 && balance > amount)
balance -= amount;
}
int getBalance() {
return balance;
}
};
In the above example, the balance data member is private and cannot be directly manipulated. It can only be accessed and manipulated through the public methods: deposit(), withdraw(), and getBalance(). If attempted directly, the program will result in compile error. This is the power of Encapsulation.
Abstraction
Abstraction is about reducing the complexity by hiding unnecessary details from the user. This allows the user to implement more complex logic while keeping things simple.
Consider a real-world example of a car. To operate a car, you need to know how to manipulate the brakes, gas pedal and steering wheel (interfaces). You do not need to know how the transmission, engine, and brakes (hidden parts) function internally. They can change and evolve independently of the person who drives the car. This concept of keeping what is necessary and hiding the inner details is called Abstraction.
In terms of programming, we achieve abstraction using interfaces and abstract classes.
Interfaces give a contract for a class to fulfill without bothering HOW it will be achieved. Just the outline of the methods is provided by the interface and the actual implementation is done in the classes.
Objects in C++ are never of an abstract class type, because such classes are meant to be inherited by other classes that implement the pure virtual function, thereby making them non-abstract.
#include <iostream>
// Abstract class
class AbstractEmployee {
virtual void askForPromotion() = 0;
};
class Employee : AbstractEmployee {
private:
std::string name;
std::string company;
int age;
public:
void setName(std::string name) {
this->name = name;
}
std::string getName() {
return name;
}
void setCompany(std::string company) {
this->company = company;
}
std::string getCompany() {
return company;
}
void setAge(int age) {
if (age >= 18)
this->age = age;
}
int getAge() {
return age;
}
// Implementation of pure virtual function.
// Override keyword from before isn't needed
void askForPromotion() {
if (age > 30)
std::cout << getName() << " got promoted!" << std::endl;
else
std::cout << "Sorry, No promotion for " << getName() << std::endl;;
}
Employee(std::string name, std::string company, int age) {
this->name = name;
this->company = company;
this->age = age;
}
};
int main() {
Employee employee1 = Employee("Josh", "Google", 18);
Employee employee2 = Employee("Angelina", "Google", 31);
employee1.askForPromotion();
employee2.askForPromotion();
return 0;
}
In this example, Employee is the concrete class that provides the implementation for the pure virtual function in the AbstractEmployee abstract class.
Understanding encapsulation and abstraction can help you design your code in a better and more effective way by providing security to your data and reducing complexity.
Templates
One of the powerful features of C++ is its support for templates. Templates are a tool for generic programming, which allows the programmer to write code that can handle any type, not just a single, predetermined type.
Consider a situation where you want to create a function to compare two integers, and another function to compare two floats. Though the logic would exactly be the same, due to the difference in data type, we will need two functions. This leads to redundant code. Here is where Templates step-in.
A template is a blueprint or formula for creating a generic class or a function. The library containers like iterators and algorithms are examples of generic programming and have been developed using template concept. There is a single definition of each container, such as vector, but we can define many different kinds of vectors for example, vector
Function templates
Function templates allow you to create a single function that can be used with different types of data. Let's say you're writing a function to find the maximum of two numbers, you'd likely start with an integer function:
int max(int a, int b) {
return (a > b)? a : b;
}
But what if you want to find the maximum of two floating-point numbers or even two characters? One approach could be writing separate functions for each type, but it's not practical. Instead, you could use a function template!
#include <iostream>
// template function max
template <typename T>
T max(T a, T b) {
return (a > b) ? a : b;
}
int main() {
int i1 = 5;
int i2 = 10;
float f1 = 5.5;
float f2 = 10.5;
char c1 = 'a';
char c2 = 's';
// call function template with int, float and char types
std::cout << "Max of " << i1 << " and " << i2 << " is " << max(i1,i2) << std::endl;
std::cout << "Max of " << f1 << " and " << f2 << " is " << max(f1,f2) << std::endl;
std::cout << "Max of " << c1 << " and " << c2 << " is " << max(c1,c2) << std::endl;
return 0;
}
In this example, the word template introduces a template function. T is a placeholder for data type - it represents whatever type you will use when you call the function. Note, that T is by convention, you could use any valid placeholder naming.
To use this function, you just call it with the data type replaced with T:
Class templates
Just like function templates, class templates allow you to create a single class definition that works with different data types.
Let's say you want to create a simple Box class that stores items of any type:
template <typename T>
class Box {
T item;
public:
void setItem(T newItem) {
item = newItem;
}
T getItem() {
return item;
}
};
You can then create objects of various 'types' from this class:
#include <iostream>
#include <string>
// template class Box
template <typename T>
class Box {
T item;
public:
void setItem(T newItem) {
item = newItem;
}
T getItem() {
return item;
}
};
int main() {
// Box that stores integer
Box<int> intBox;
intBox.setItem(123);
std::cout << "Integer stored in box: " << intBox.getItem() << std::endl;
// Box that stores string
Box<std::string> stringBox;
stringBox.setItem("Hello World");
std::cout << "String stored in box: " << stringBox.getItem() << std::endl;
return 0;
}
A key thing to remember here is templates are expanded at compile time like macros. The compiler does type checking before template expansion, i.e., at compile time.
Templates provide a way to re-use your code with both built-in types (like int, float, etc.) and user-defined types. They're a powerful tool for saving time and reducing code redundancy, but also require careful use due to increased compilation time.
Namespaces
Just as we organize files in directories to avoid name clashes, we use namespaces in C++ to avoid name conflicts in our program. A namespace is a declarative region that provides a scope to the identifiers (the names of types, functions, variables, etc) inside it. They allow us to group named entities that otherwise would have global scope into narrower scopes, giving them namespace scope.
Declaring Namespaces
To declare a namespace, we use the namespace keyword followed by the name we want for our namespace and a body enclosed in {}.
namespace MyNamespace {
// code declarations
}
Inside the namespace, you can declare variables, functions, classes and even another namespace, known as a nested namespace.
Using Namespaces
To access the code inside a namespace, we use the scope resolution operator ::. So, if we wanted to access a variable x inside MyNamespace, we would do MyNamespace::x.
#include <iostream>
namespace MyNamespace {
int x = 5;
}
int main() {
std::cout << MyNamespace::x << '\n';
return 0;
}
Using Directives
We can include an entire namespace in our code with using the using keyword. However, this approach is generally not recommended for large programs, as it can lead to name conflicts. Particularly, using using namespace std; is considered a bad practice, as it may lead to conflicts with names in the standard library.
using namespace MyNamespace;
After doing above, you can access variables directly - x instead of MyNamespace::x.
Using Declarations
If you only need one or two items from a namespace, you can introduce them into your code with using followed by the fully qualified name.
using MyNamespace::x;
Just like with the using directive, you'd now be able to access x directly.
Namespace Aliases
If you're working with namespaces that have long or complicated names, you can create an alias to make it easier to write:
namespace MN = MyNamespace;
Now you can use MN::x instead of MyNamespace::x.
Namespaces are an effective way to avoid naming conflicts in large programs, especially when using multiple libraries. However, care should be taken when introducing entire namespaces into your program to avoid potential naming conflicts.
Exception Handling
In programming, things don't always go as planned. Sometimes, errors occur, like trying to open a file that doesn't exist or dividing a number by zero. In C++, we have a way to deal with these unexpected events called exception handling.
Exception handling uses special code blocks to "catch" errors and deal with them so your program can keep running or shut down nicely instead of crashing. Imagine using a safety net to catch an acrobat if they fall; this is what exception handling does for your program!
In this section, we’ll cover the basics of how to work with these safety nets. We’ll learn how they help us find and handle the unexpected without making everything else complicated.
Use of try, catch, and throw
In C++, error handling is an essential aspect of program design. When an error occurs within a program, we want to handle it gracefully rather than allowing the program to crash. To address errors, C++ provides a mechanism known as exception handling, which is built around three keywords: try, catch, and throw.
Exception handling allows a program to catch and handle errors in a controlled way. It separates the error-handling code from the regular code, making your code cleaner and easier to maintain. Moreover, it provides a way to pass an error up the call stack, potentially allowing for a higher-level function to handle the problem if the current context cannot.
The try Block
A try block defines a section of code in which exceptions may occur. It is followed by one or more catch blocks. When an exception is thrown within the try block, control is transferred to the appropriate catch block where the error can be addressed.
The throw Keyword
To signal that an error has occurred, we use the throw keyword followed by an exception object. The exception object can be of any type, but it's often an instance of std::exception or a subclass thereof.
The catch Block
A catch block catches an exception thrown from a try block and contains code to handle the error. Each catch block is associated with a type of exception, which it is equipped to handle.
Why Use Exception Handling Over Other Methods
Prior to exceptions, errors were commonly handled using return codes or global error flags that had to be checked after every operation that could fail. This leads to cluttered code, as error handling is mingled with regular logic, and it's easy to forget to check a return code, leading to unhandled errors.
Exception handling centralizes error-handing code and separates it from the main logic, making it more readable and maintainable. It also allows errors to "bubble up" to higher levels where they can be handled appropriately instead of requiring immediate handling after every operation.
Exception handling is also a clear signal of handling "exceptional" circumstances that are not expected to happen often, which distinguishes it from regular control flow.
Example: Using try, catch, and throw
Let's imagine we have a function that divides two numbers. However, division by zero is an error in mathematics, and thus we should handle it as an exception in our code.
#include <iostream>
#include <stdexcept> // For std::runtime_error
int divide(int numerator, int denominator) {
if (denominator == 0) {
throw std::runtime_error("Division by zero error");
}
return numerator / denominator;
}
int main() {
try {
int result = divide(10, 0);
std::cout << "Result is: " << result << std::endl;
} catch (const std::runtime_error& e) {
std::cerr << "Caught an exception: " << e.what() << std::endl;
}
return 0;
}
When running this code, the division by zero will throw an exception, which is then caught and handled in the catch block, printing the error message without crashing the program.
By building your C++ applications with consistent and thoughtful use of exception handling, you can ensure they are more robust, easier to debug, and provide clear and helpful feedback to the user or other developers working on the codebase.
Understanding the Call Stack and Exception Propagation
The call stack is an important concept in the execution of a program; it's a stack data structure that keeps track of active subroutines (or functions) within the program. This is the place where the program stores information about the sequence of function calls that are in progress, ensuring that each function returns control to the function that called it.
Here's a step-by-step explanation on how the call stack works:
- When a function is called, an entry is made on the top of the call stack—this entry is often called a "stack frame" or "activation record."
- This stack frame contains information such as the function's parameters, its local variables, and the address in the code to return to when the function exits.
- Once a function completes its task, its stack frame is "popped" off the call stack, and the program resumes execution at the return address that was stored in the popped stack frame.
Now, when it comes to exceptions and the call stack:
- When an exception is thrown using the
throwkeyword, it disrupts the normal sequential execution of code. - The runtime system starts unwinding the call stack, checking for a
catchblock that can handle the thrown exception. This is often referred to as "exception propagation" or "stack unwinding." - As the unwinding occurs, if the current stack frame has no
catchblock that matches the exception, it is popped off the call stack, and the runtime looks in the next stack frame. - This process continues "up" the call stack until a suitable
catchblock is found. If no such block is encountered and the exception reaches the main function, then the default behavior is that the program will terminate.
By using exception handling with try, catch, and throw, you allow your program to handle errors at the most appropriate level within the call stack, without cluttering lower-level functions with error-handling logic that is better handled by higher-level functions. This approach leads to cleaner, more modular, and more maintainable code.
Custom Exceptions
In C++, we can create our own exception classes by deriving from the standard exception classes provided by the <stdexcept> library. Custom exceptions allow for more specific error handling and can provide additional information about the error that occurred.
Why Create Custom Exceptions?
Custom exceptions are beneficial when you want to:
- Categorize errors into more specific types beyond the general exceptions provided by the standard library. This can make your code more readable and your error handling more tailored to specific problems.
- Carry more information about the error. You can add more data members to provide details like error codes, timestamps, or context-specific messages.
- Enforce a certain style of exception handling within your application or library, ensuring that all parts of your program handle errors consistently.
- Distinguish between internal and external library errors, which can aid in better debugging and maintenance.
Defining a Custom Exception
Custom exceptions are defined like any other class. They should inherit from an appropriate standard exception class, typically std::exception or one of its derived classes like std::runtime_error.
#include <stdexcept>
#include <string>
class DivisionException : public std::runtime_error {
public:
DivisionException(const std::string& message)
: std::runtime_error(message) {}
};
Throwing a Custom Exception
To throw a custom exception, you simply throw an instance of your custom exception class, just like you would with a standard exception.
Catching a Custom Exception
Catching a custom exception is identical to catching a standard exception. You use a catch block that specifies the type of the custom exception.
#include <iostream>
#include <string>
class DivisionException : public std::runtime_error {
public:
DivisionException(const std::string& message)
: std::runtime_error(message) {}
};
int divide(int numerator, int denominator) {
if (denominator == 0) {
throw DivisionException("Division by zero detected");
}
return numerator / denominator;
}
int main() {
try {
int result = divide(10, 0);
std::cout << "Result is: " << result << std::endl;
} catch (const DivisionException& e) {
std::cerr << "Caught a division exception: " << e.what() << std::endl;
} catch (const std::exception& e) {
std::cerr << "Caught a standard exception: " << e.what() << std::endl;
}
return 0;
}
In this example, if division by zero is attempted, a DivisionException is thrown. The catch block for DivisionException will handle this specific exception, providing a clear message about the error. If another type of exception is thrown, the more generic std::exception catch block can handle it.
Custom exceptions can greatly enhance the exception handling capability of your C++ application, making it easier to understand, debug, and maintain your error-handling code
Memory Management in C++
Memory management is an integral part of developing applications in C++. It's the practice of controlling how the memory in a computer program is allocated, used, and freed. Proper memory management is critical because it directly impacts program performance and stability.
Just as a strong foundation is necessary when constructing a house, a solid understanding of memory management is crucial for building reliable and efficient C++ programs.
Stack vs Heap Memory Allocation
Understanding memory allocation is essential when diving into C++ programming. Let's explore two key areas where memory is allocated: the stack and the heap. Both serve different purposes in a program's life cycle and have various access patterns and management styles.
Stack Memory Allocation
The stack is an area of memory that stores temporary data such as function parameters, return addresses, and local variables. It operates on a last-in, first-out (LIFO) model, which means that data added last will be the first to be removed when no longer needed.
void someFunction() {
int localVar = 5; // Allocated on the stack
// 'localVar' is only visible within 'someFunction'
} // 'localVar' is automatically deallocated when 'someFunction' returns
Advantages of Stack Memory:
- Fast Allocation: Memory management on the stack is simple and thus very fast.
- Automatic Memory Management: Once the scope ends, variables on the stack are automatically deallocated.
Disadvantages of Stack Memory:
- Size Limitation: Stack size is limited and can lead to stack overflow if exceeded.
- Local Scope: Memory on the stack can only be used within the function that allocated it.
Heap Memory Allocation
The heap is a pool of memory used for dynamic allocation. Unlike stack variables, which are managed automatically, heap variables need to be explicitly allocated and deallocated by the programmer.
int* heapVar = new int; // Allocate memory for an integer on the heap
*heapVar = 5; // Store 5 in the allocated memory
// ... Use 'heapVar' as needed ...
delete heapVar; // Deallocate memory when done
Advantages of Heap Memory:
- Large Amounts of Memory: The heap can provide large blocks of memory that would not fit on the stack.
- Persistent until Deallocated: Memory on the heap remains allocated until it is explicitly deallocated or the program ends.
Disadvantages of Heap Memory:
- Slower than Stack: Accessing memory on the heap is slower than stack memory access.
- Manual Management: The programmer is responsible for allocating and deallocating heap memory, which can lead to errors.
C-Style Memory Allocation with malloc
Before C++, the C language used malloc() to allocate memory dynamically. malloc() does not call constructors and therefore is not suitable for non-POD (plain old data) types in C++.
Example: C-Style Allocation
#include <cstdlib> // Required for malloc and free
int* cStyleVar = (int*)malloc(sizeof(int)); // Allocates enough memory for an int
if (cStyleVar != nullptr) {
*cStyleVar = 5; // Use the allocated memory to store the value 5
}
// ... Work with 'cStyleVar' ...
free(cStyleVar); // Deallocate memory with free
The sizeof operator in these examples is used to calculate the size in bytes of a type or object. In the above case, sizeof(int) provides the amount of memory required to store one integer.
The malloc function in C-style memory allocation is used for dynamically allocating a block of memory on the heap. It takes the size of the memory needed (in bytes) as a parameter, and it returns a pointer to the beginning of that block of memory.
In modern C++, malloc and free are generally discouraged. Instead, the language provides operators new and delete for dynamic memory allocation, which ensure that object constructors and destructors are properly called. For safer memory allocation, developers are further encouraged to use smart pointers which we will talk about in the next section.
Unique Pointers
Smart pointers are a key feature of modern C++ that handle the allocation and deallocation of memory for you. std::unique_ptr is particularly useful because it manages a dynamically allocated object and automatically deletes the object when the std::unique_ptr goes out of scope.
Benefits of std::unique_ptr
- Automatic Resource Management: Automatically frees the associated memory without needing explicit
deletecalls. - Exclusive Ownership: Ensures there's exactly one owner for the allocated memory, avoiding potential issues with multiple deletions.
- Move Semantics: Enables safe transfer of ownership from one
std::unique_ptrto another.
Creating and Using std::unique_ptr
Use std::make_unique to create a std::unique_ptr in a safe and convenient way.
Example: Using std::make_unique
#include <iostream>
#include <memory>
int main() {
auto uniquePtr = std::make_unique<int>(10); // Create a unique_ptr managing an int
std::cout << "Value: " << *uniquePtr << std::endl; // Use the managed object
// uniquePtr is automatically freed when going out of scope
return 0;
}
std::make_unique is the preferred method to create a std::unique_ptr because it ensures memory safety, even in cases where exceptions might occur.
Transferring Ownership with Move Semantics
Since std::unique_ptr cannot be copied, the ownership of the managed memory can be transferred using move semantics, by using the std::move function.
Example: Moving a std::unique_ptr
#include <iostream>
#include <memory>
void processPointer(std::unique_ptr<int> ptr) {
std::cout << "Processing value: " << *ptr << std::endl;
// ptr will be automatically freed when the function scope ends
}
int main() {
auto owner = std::make_unique<int>(20);
processPointer(std::move(owner)); // Moves the ownership to processPointer
if (owner) {
std::cout << "Owner still has the unique_ptr." << std::endl;
} else {
std::cout << "Owner no longer has the unique_ptr." << std::endl;
}
// Safe to exit main, no manual delete needed
return 0;
}
Move semantics in C++ allow you to efficiently transfer ownership of resources (like dynamically allocated memory) from one object to another. Instead of copying the data, moving an object transfers its internal data to a new object and leaves the original object in a valid but unspecified state (often empty or null). This process is especially important for managing resources in a safe and performance-optimized manner.
Remember, when using std::unique_ptr, no need to worry about delete, thanks to its automatic memory management. This smart pointer ensures that your dynamically allocated memory is released when it’s no longer needed, which helps you to avoid memory leaks and keep your resource management clean and straightforward.
Shared Pointers
std::shared_ptr is another type of smart pointer provided by the C++ standard library to manage dynamically allocated objects. Unlike std::unique_ptr, std::shared_ptr allows multiple shared pointers to point to the same object. The object is automatically destroyed and its memory deallocated when the last std::shared_ptr owning it is destroyed or reset.
The Concept of Reference Counting
std::shared_ptr uses an internal reference count mechanism to keep track of how many std::shared_ptr instances own the same resource. When a new std::shared_ptr is created from another, the reference count is incremented. When a std::shared_ptr is destructed, the count is decremented. Once the count reaches zero, meaning no std::shared_ptr owns the resource, the resource is destroyed.
Advantages of std::shared_ptr
- Shared Ownership: The resource can be shared by multiple
std::shared_ptrinstances, enabling more flexible memory management. - Automatic Memory Management: Like
std::unique_ptr,std::shared_ptrautomatically releases the memory when no longer needed. - Thread Safe: The reference count mechanism is thread-safe (except for simultaneous reads and writes to the same
std::shared_ptr).
Usage of std::shared_ptr
Use std::make_shared to create a std::shared_ptr. This function will allocate the object and initialize the reference count.
It's important to note that std::make_shared is more efficient than separately allocating the object and the internal control block because it can perform a single heap allocation for both, reducing the overhead and improving performance.
Caveats with std::shared_ptr
While std::shared_ptr is quite powerful, it's important to be aware of potential pitfalls:
- Cyclic References: If circular references are created (e.g., two or more
std::shared_ptrinstances own each other directly or indirectly), the reference count can't reach zero, leading to memory leaks. - Performance Overhead: The extra control block, reference counting, and thread-safe increment/decrement operations introduce overhead compared to
std::unique_ptr.
Using Custom Deleters
std::shared_ptr and std::unique_ptr can both be used with a custom deleter.
std::shared_ptr is an incredibly versatile tool. By understanding how to properly create, use, and avoid pitfalls with std::shared_ptr, you can safely manage shared resources in complex C++ applications.
Weak Pointers
std::weak_ptr is a smart pointer that holds a non-owning ("weak") reference to an object that is managed by std::shared_ptr. It is designed to be used in conjunction with std::shared_ptr to overcome certain problems with shared ownership, particularly the issue of cyclic references.
What is std::weak_ptr?
std::weak_ptr provides a way to reference an object managed by a std::shared_ptr without increasing its reference count. This is useful when you want to observe an object, but its existence should not influence its own lifetime.
Key Features of std::weak_ptr
- Cyclic References: It helps to break cycles of
std::shared_ptrthat may lead to memory leaks. - Temporary Access: It can be used to check if an object exists before accessing it through a
std::shared_ptr.
Using std::weak_ptr
To create a std::weak_ptr, you can construct it from a std::shared_ptr. To actually work with the underlying object, you must convert the std::weak_ptr to a std::shared_ptr using the lock method, which creates a shared ownership only if the managed object has not been deleted.
#include <iostream>
#include <memory>
class Example {
public:
void showMessage() { std::cout << "Message from object." << std::endl; }
~Example() { std::cout << "Example object destroyed." << std::endl; }
};
int main() {
std::weak_ptr<Example> weakPtr;
{
auto sharedPtr = std::make_shared<Example>();
weakPtr = sharedPtr; // weakPtr points to "Example" object
if (auto tempSharedPtr = weakPtr.lock()) {
// Converts to shared_ptr to check and use the object
tempSharedPtr->showMessage();
} else {
std::cout << "The object no longer exists." << std::endl;
}
}
// sharedPtr goes out of scope, "Example" object is destroyed
// Checks if the object weakPtr points to is already destroyed
if (weakPtr.expired()) {
std::cout << "The object has been destroyed." << std::endl;
}
return 0;
}
Advantages of std::weak_ptr
- Avoids Cyclical References: By using
std::weak_ptrfor back-pointers, you can avoid cyclical references that cause memory leaks. - Safe Object Observers: It provides a safe way to observe an object that might get deleted by another part of the program.
Disadvantages of std::weak_ptr
- No Direct Access: You cannot directly access the object a
std::weak_ptrrefers to; you must convert it to astd::shared_ptrfirst. - Extra Check Required: Before using the managed object, you have to perform an additional check to see if the object still exists.
Using std::weak_ptr can significantly increase the robustness of your programs when dealing with complex data structures that involve shared ownership. It is a powerful tool that should be understood and utilized to write high-quality C++ code without memory management issues.
Lambda Expressions
In C++, lambda expressions are a concise way to write anonymous functions. These unnamed, small functions can be defined inline within the code where they are used, making them particularly useful for short snippets of code that are passed to algorithms or used for implementing callbacks.
Lambda expressions can capture variables from their surrounding scope, support parameter declaration, and can have a return type inferred by the compiler. They provide a powerful way to define function objects quickly.
Syntax of Lambda Expressions
The general syntax of a lambda expression looks like this:
[ capture_clause ] ( parameters ) -> return_type {
// function body
}
Here's a breakdown of the lambda expression syntax:
- Capture Clause (
[]): This part is used to specify which variables from the surrounding scope are available inside the lambda, and whether they are captured by value or by reference. - Parameters (
()): Just like regular functions, you can pass parameters to a lambda. - Mutable Specification (
mutable): If you need to modify the captured variables within the lambda, you can specifymutableafter the parameter list. - Return Type (
->): You can specify the return type of the lambda. If omitted, it will be inferred from the return statements in the function body. - Function Body (
{}): The code to be executed when the lambda is invoked goes here.
Examples of Lambda Expressions
Simple Lambda Without Capture
auto greet = []() {
std::cout << "Hello, World!" << std::endl;
};
greet(); // Output: Hello, World!
Lambda With Capture By Value
int x = 10;
auto add_to_x = [x](int y) {
return x + y;
};
std::cout << add_to_x(5); // Output: 15
Lambda With Capture By Reference
int x = 10;
auto add_to_x = [&x](int y) {
x += y; // Modifies the original 'x'
};
add_to_x(5);
std::cout << x; // Output: 15
When you use lambda expressions in C++, capturing local variables by reference (&) can lead to potential issues if the lambda outlives the scope of the variables it captures. This is similar to the problem of dangling pointers or references.
Here's an important caution: If a lambda captures variables by reference and is stored for use later—such as passing it to a function that might execute the callback asynchronously, or storing it for future use—there's a risk that the captured references will become invalid. If the function that created the local variables finishes execution, the references held by the lambda will refer to destroyed variables, leading to undefined behavior when accessed.
This might manifest as accessing a nullptr, segmentation faults, or other erratic behavior, because you're trying to use data that no longer exists.
Example of Dangerous Lambda Capture by Reference:
#include <iostream>
#include <functional>
std::function<void()> create_dangerous_lambda() {
int local_var = 42;
// Capture by reference is risky here!
auto lambda = [&local_var]() {
std::cout << local_var << std::endl; // DANGER: 'local_var' may not exist!
};
return lambda; // Returning lambda that keeps a reference to 'local_var'
}
int main() {
auto dangerous_lambda = create_dangerous_lambda();
// Now 'dangerous_lambda' holds a reference to 'local_var' which is out of scope.
dangerous_lambda(); // UNDEFINED BEHAVIOR: Accessing a reference to a destroyed variable.
return 0;
}
To avoid such issues, you can:
- Capture by value instead of by reference when you expect the lambda to outlive the scope of local variables.
- Use
std::shared_ptrorstd::unique_ptrfor dynamic memory allocation if the lambda needs to manage the lifetime of the coped object. - Ensure that the lifetime of the referenced variables is extended to match the lifetime of the lambda, which can be complex and is generally not recommended.
Lambda expressions are incredibly powerful, but with that power comes a responsibility to manage captured variables' lifetimes carefully to prevent unsuspecting bugs and crashes.
Lambda With a Specified Return Type
auto divide = [](double a, double b) -> double {
if (b == 0) {
throw std::runtime_error("Division by zero!");
}
return a / b;
};
std::cout << divide(10, 2); // Output: 5
Lambda Used as a Comparator in std::sort
std::vector<int> numbers = {4, 2, 3, 1, 5};
std::sort(numbers.begin(), numbers.end(), [](int a, int b) {
return a < b;
});
// Now 'numbers' is sorted in ascending order
Advantages of Lambda Expressions
Lambda expressions are favored in modern C++ because they enable us to:
- Write shorter and cleaner code, making it more readable.
- Avoid the overhead of creating named function objects when a quick, one-time function is needed.
- Have better encapsulation and locality of behavior within the code.
- Easily work with generic programming and the Standard Template Library (STL).
With lambdas, C++ code that relies on function pointers, functors, or callbacks becomes more intuitive and manageable. Lambda expressions are therefore a powerful feature for any C++ programmer to understand and use effectively.